Reverse engineering, реверс или по-просту обратная разработка для самых маленьких и ленивых. Часть 1

Эта тема очень не простая, но на мой взгляд обязательная даже для начинающих, которые приняли твердое решение встать на путь ИБ, необходимо иметь хотя бы базовое понимание вопроса. В этой теме затрагиваются рудиментарные принципы работы компьютеров, архитектуры процессоров, операционных систем и их взаимодействия. Другими словами, для того, чтобы быть водителем – совсем не обязательно знать каждую деталь автомобиля, но понимание принципов его работы в целом и каждого из механизмов в частности – потребуется.
В статьях про “бинарщину” мы затронем самое базовые функции работы ПК, затроним таие понятия как “реверс”, намного разберемся с ассемблером и устройством центрального процессора ПК.
Начнём с определения в википедии.
Обратная разработка (обратное проектирование, обратный инжиниринг, реверс-инжиниринг; англ. reverse engineering) — исследование некоторого готового устройства или программы, а также документации на него с целью понять принцип его работы; например, чтобы обнаружить недокументированные возможности (в том числе программные закладки), сделать изменение или воспроизвести устройство, программу или иной объект с аналогичными функциями, но без прямого копирования.
Это можно дополнить тем, что обратная разработка также служит для поиска уязвимостей в ПО или устройстве.
Обратная разработка на простом примере
Вы получаете квадратную коробку, с одной стороны у коробки есть ручка, регулируя которую, вы выставляете различные значения на вход, после фиксации ручки вы можете нажать на копку и получить значение на другой стороне коробки, которая считается выходом. То есть по сути у вас есть чёрный ящик, которому вы можете предоставлять входные данные и получать выходные.
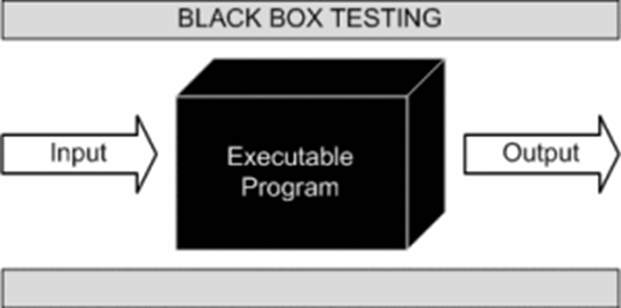
Теперь представим, что вам дали только этот ящик и никаких документов к нему нет, то есть, как он работает, вы не знаете, вы просто можете подавать значения на вход и получать значения на выходе, как они связаны вы не понимаете, но хотите разобраться. Зачем? Ну, например, для того, чтобы сделать такой же ящик или чтобы найти в ящике ошибку – момент, когда он будет выдавать одинаковые результаты на разные входные данные, хотя так не должно быть, или что-то другое. Ваши цели могут быть совсем иные, важно лишь то, что вам нужно понять, как он работает или как работают его отдельные части.
Чтобы решить эту проблему, вы можете использовать разные варианты, например, вы можете проанализировать связь входных и выходных данных и найти формулу, по которым они меняются, но здесь вас может подстерегать проблема: вдруг внутри машины есть заранее определённые константы, о которых вы не знаете, да и для подтверждения вашей формулы вам придётся проверить все пары входных и выходных данных, а их может быть очень много.
Хорошим решением данной проблемы будет разбор ящика и анализ его внутреннего устройства. Для разбора ящика необходимы инструменты, а они могут быть различны в зависимости от задач, однако есть основные мультизадачные инструменты. Например, с помощью отвёртки можно раскрутить каркас ящика, крепления внутренних элементов, полностью разобрать его и достать необходимые элементы наружу, однако мы всё равно не получим представление о работе ящика, если просто всё вытащим из него. Нам необходимо проанализировать взаимосвязь всех компонентов при их совместной работе, в идеале понять через какие элементы ящика проходят наши входные значения, как преобразуются и как обрабатываются на различных этапах, в общем, полностью понять алгоритмы обработки наших значений. Лучшим вариантом, конечно, будет, пошаговое наблюдение за работой ящика, однако это не всегда возможно как в ящиках, так и в реальных анализах программ.
Считается, что обратная разработка является самой сложной частью информационной безопасности, наверное, так и есть, ведь, чтобы действительно проводить полноценные исследования, нужно знать очень много фундаментальных вещей, начиная от построения процессора и заканчивая алгоритмами и их реализациями, поэтому данная тематика считается очень сложной, но надо заметить, что и оплачивается соответственно.

Перед тем как мы перейдём непосредственного к исследованию нашей первой программы, мы вспомним основы информатики, работы ЦП, устройства ОС и исполняемых файлов, вспомним про низкоуровневые языки программирования (далее ЯП) и многое другое. Всё это необходимо для того, чтобы у вас было хотя бы малейшее представление и понимание того, что вы должны будете сделать при исследовании приложения.
Начнём с простого
Повторим, что такое ЦП (центральный процессор) и для чего он нужен.
Итак, ЦП служит для выполнения команд компьютером, он по сути выполняет ряд заложенных в него на стадии производства команд, современные процессоры могут выполнить за раз огромное количество операций.
Все операции процессора очень просты, например, сложить два регистра (переменные) или выдать значение на шину данных, положить в регистр значение, взять значение с шины данных и другие простейшие операции. Были упомянуты следующие, возможно, незнакомые вам определения: регистр, шина данных, они будут объяснены далее.
Нужно помнить, что фактически процессор воспринимает только последовательности 0 и 1, то есть он работает на очень низком уровне и оперирует только бинарным кодом.
В зависимости от архитектуры длины команд могут быть различны, могут иметь фиксированную длину (так называемая RISC-архитектура), либо иметь нефиксированную длину команды (например, x86, x86-64). Человеку сложно воспринимать просто числа и считать их командами, для него нужна более высокая абстракция, которой как раз и является язык Ассемблера.
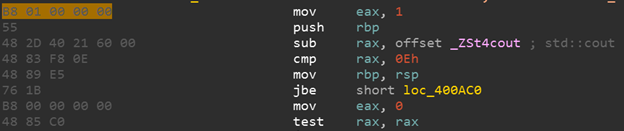
Язык Ассемблера различен для различных архитектур процессоров. Язык ассемблера напрямую связан с двоичными кодами команд процессора, то есть каждая команда на ассемблере имеет однозначное прямое соответствие с опкодом процессора (опкод – это операционный код, довольно частое применяется для описания одной команды процессора). Посмотрим на примере. У нас есть команда на языке ассемблера для архитектуры x86-64:
mov eax, 1 – что означает положи в регистр eax значение 1
В шестнадцатеричном представлении опкодов эта команда будет выглядеть так:
B8 01 00 00 00
Видно, что ассемблерное представление удобнее для человека и позволяет лучше понять, что происходит в данном участке кода.
На изображении ниже, слева вы можете увидеть шестнадцатеричное представление опкодов, а справа представление на языке ассемблера.
Вывод
- Обратная разработка – исследование (с различными целями) ПО или устройства
- Центральный процессор выполняет команды, представленные в виде 0 и 1 (бинарный вид)
- Для удобства представления команд процессора используется язык ассемблера
- Однак команда на языке ассемблера соответствует одной процессорной команде
- Язык ассемблера уникален для каждой из существующих архитектур
Процессор, строение
Процессор помимо устройства управления и АЛУ (арифметико-логическое устройство) содержит также запоминающее устройство, которое включает в себя регистры – небольшие ячейки сверх быстрой оперативной памяти (СОЗУ), которые используются самим процессором для выполнения каких-либо операций, в зависимости от архитектуры размер ячеек, их количество и общепринятые названия меняются. Также существуют регистры общего назначения и специальные регистры. Фактически можно сделать довольно сильное упрощение и просто представлять себе регистры, как переменные без типа, с фиксированным размером, доступ к которым осуществляется мгновенно.
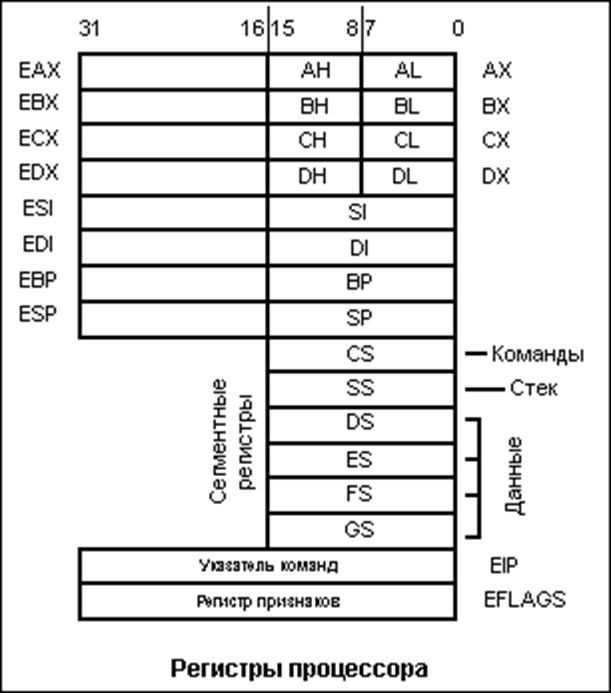
Для базового представления о регистрах, надеюсь данной информации хватит, однако рекомендую поподробнее ознакомиться с данной темой (ссылки: https://en.wikipedia.org/wiki/Processor_register, https://en.wikipedia.org/wiki/Central_processing_unit).
Теперь мы примерно понимаем, как работает процессор, и у нас может возникнуть вопрос, как процессор отличает данные от команд, ведь по сути вся информация в компьютере является числами, которые так или иначе можно передать процессору в качестве команд. На самом деле эту проблему решает ОС, регулируя файлы через их формат. На рисунке ниже представлено краткое описание формата PE для OC Windows. Например, если вы откроете в шестнадцатеричном редакторе две разные картинки с одинаковыми расширениями, то увидите, что в заголовках этих картинок будут находиться одинаковые байты, за исключением конечно байтов, связанных с расширением. ОС понимает по расширению файла, что этот файл не является исполняемым, однако расширение можно принудительно поменять, например, на *.exe (расширение исполняемых файлов в Windows), тогда ОС будет думать, что это файл исполняемый, однако при попытке его запуска возникнет ошибка из-за того, что формат файла другой, ОС будет искать определённые секции в файле, необходимые заголовки и не найдёт их, так как мы просто поменяли расширение у картинки, а не полностью формат файла. Таким образом и регулируются команды, которые поступают к процессору.
Формат исполянемого файла
Разные ОС имеют разный формат исполняемых файлов: для Windows – это формат PE, для Linux – это формат ELF, для OS X – это формат Mach-O. Что это означает на практике? Если мы имеем одинаковый исходный код программы на 3-х разных ОС, её скомпилированный вид будет различным.
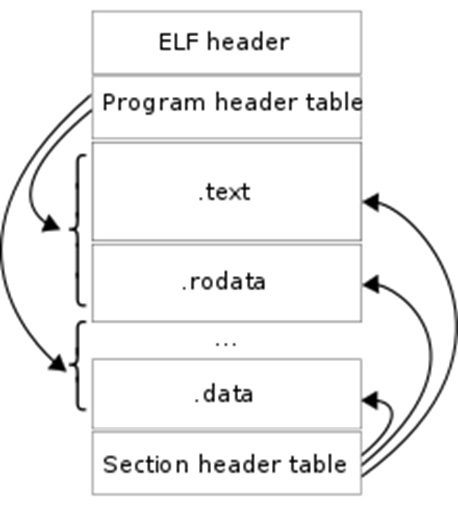
То есть скомпилированная программа из одного исходного кода на одном и том же процессоре, но под разные ОС, будет различна в каждом случае. Запустить программу, скомпилированную под Linux на Windows, не представляется возможным, без использования специальных средств. Всё это происходит из-за того, что каждая операционная система имеет свой формат исполняемого файла. Формат – это набор определённых правил построения исполняемого файла, например, заголовок должен содержать определённую сигнатуру на такой-то позиции, потом идёт размер секций, потом – сами секции.
Файл строится по неким единым правилам для того, чтобы ОС при запуске файла смогла верно загрузить его в ОЗУ и передавать ЦП верные инструкции, которые находятся в этом файле, также ОС будет предоставлять исполняемому файлу необходимые библиотеки, данные и прочее. Всё это ОС поймёт из содержания файла, так как он построен по правилам формата исполняемого файла для данной ОС. Советую также самостоятельно ознакомиться с форматами исполняемых файлов, например, с форматом ELF (https://ru.wikipedia.org/wiki/Executable_and_Linkable_Format).
Теперь перейдём к тому, как получить исполняемый файл. Этот процесс называется компиляцией, и вы должны уже быть с ним знакомы с курса программирования на С++.
Компиляция
Процесс преобразования исходного кода на каком-либо компилируемом ЯП высокого или среднего уровня в машинные коды называется компиляцией. По сути это превращение нашего файла с исходным кодом, например, на языке С, в исполняемый файл под Windows, который можно будет запустить и увидеть, как он исполнит заданные нами команды в исходном коде. Теория компиляции очень сложна, в некоторых ВУЗах на это отводят целые дисциплины в несколько семестров, однако нам нужно знать лишь некоторые фундаментальные моменты компиляции, но если вы хотите углубиться в эту сферу, то учтите, что вам придётся очень хорошо выучить математику.
Что нам интересно для наших целей: Во-первых, компиляция — это однонаправленный процесс, который невозможно полностью достоверно обратить, то есть по имеющимся машинным командам мы не сможем получить код на языке С или С++, так как процесс компиляции — это процесс с потерями. Во-вторых, если вы хотите внести какие-либо изменения в программу и править исходный код, то для внесения этих изменений в скомпилированную программу, необходимо перекомпилировать её. В-третьих, в скомпилированной программе отсутствуют такие понятия, как переменные, функции, циклы и прочее, скомпилированная программа это набор машинных инструкций. Пожалуй, это основные моменты, которые нам необходимы. Относительно полная схема компиляции изображена на рисунке ниже.
Может возникнуть вопрос: “Если невозможно получить исходные коды из скомпилированного приложения, то как мы будем его исследовать?”. Данный вопрос подводит нас к процессу преобразования скомпилированного приложения в человеко-читаемый вид. Этот процесс называется дизассемблирование.
Дизассемблирование
Процесс преобразования (трансляции) машинных кодов в текст программы на языке ассемблера называется дизассемблированием. Если вы пролистаете лекцию чуть выше, то заметите, что, когда мы описывали машинные коды, мы учли, что каждому машинному коду соответствует одна команда на языке ассемблера, соответственно мы можем перевести машинный код в код ассемблера, который поудобнее анализировать, чем последовательности нулей и единиц. Данная задача решается сегодня лишь несколькими инструментами: IDA Pro и radare2 (только под Linux). IDA Pro являет несомненным лидером в данной области, однако она является платной, а бесплатные версии обладают крайне урезанным функционалом, но мы всё равно будем использовать её в качестве основного инструмента для исследования, потому что она обладает большим спектром функций, помимо основной функции – дизассемблирования.
Для понимания того, как выполняется программа – необходимо понимать архитектуру современных компьютеров. Современные компьютеры строятся по принципам архитектуры фон Неймана:
1) Принцип однородности памяти.
Данный принцип говорит о том, что в памяти одновременно хранятся как данные программы, так и команды (код программы). Был и другой вариант данного принципа в Гарвардской архитектуре. В ней, данные и инструкции хранились отдельно друг от друга.
2) Принцип адресности.
Память программы можно представлять, как последовательность ячеек, пронумерованных целыми числами и каждую ячейку можно прочитать из памяти или записать в неё значение, просто обратившись к ней по её номеру.
3) Принцип программного управления.
Выполнение программы управляется посредством последовательности команд, эти команды выполняются одна за другой до тех пор, пока не будет выполнена специальная команда, вроде условного перехода, безусловного перехода или вызова функции.
4) Принцип двоичного кодирования.
Вся информация (данные и команды) кодируются двоичными числами.
Коротко о сегментации памяти:
Оперативная память, используемая в программах, написанных на С/С++ разделена на области двух типов:
• Сегменты данных
• Сегменты кода (текстовые сегменты)
В сегментах кода содержится код программы. Обычно данные сегменты защищаются от записи, то есть ОС следит за тем, чтобы данные находящиеся в этих сегментах не изменялись.
В сегментах данных располагаются данные программы (значения переменных, массивы и пр.).
При запуске программы выделится два сегмента данных:
• Сегмент глобальных данных
• Стек (для локальных переменных)
В процессе работы программы могут выделяться и освобождаться дополнительные сегменты памяти.
Обращение к адресу вне выделенных сегментов (к сегментам, которые не принадлежат вашей программе) – ошибка времени выполнения (access violation, segmentation fault).
Коротко рассмотрим вопрос выполнения программы
В скомпилированном коде вашей программы каждой функции будет соответствовать отдельная секция. Адрес начала этой секции – это адрес функции, тот адрес, который будет подставлен в место вызова вашей функции.
Телу функции соответствует последовательность команд процессора, которая получилась после компиляции. Работа с данными, такими как локальные или глобальные переменные происходит на уровне байт, то есть никакой информации о типах нет.
В процессе выполнения адрес каждой следующей инструкции хранится в специально регистре процессора IP (Instruction pointer), который указывает на адрес следующей инструкции. При выполнении инструкций этот регистр увеличивается и таким образом инструкции выполняются последовательно. В тот момент, когда встречается какая-либо специальная инструкция (условный/безусловный переход, вызов функции) IP изменяется и выполнение переходи на другую инструкцию, которая может быть в другом месте программы. Например, при вызове функции IP переводится на адрес начала функции.
Рассмотрим стек вызовов
Стек вызовов – это сегмент данных, используемый для хранения локальных переменных, временных значений, адресов возврата, аргументов, передаваемых в функции. Стек выделяется при запуске программы и обычно он небольшой по размеру (примерно 4 Мб).
На стеке хранятся локальные переменные функции, которая исполняется в данный момент. При выходе из функции, соответствующая область стека, где находились локальные переменные данной функции объявляется свободной, и другая функция может её перезаписать.
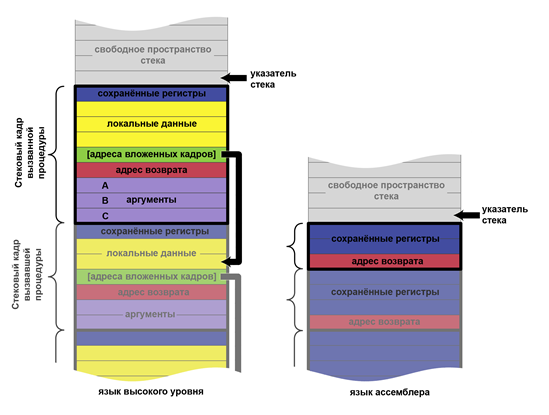
Коротко об соглашении о вызове
Соглашение о вызове — описание технических особенностей вызова подпрограмм, определяющее:
- способы передачи параметров подпрограммам;
- способы вызова (передачи управления) подпрограмм;
- способы передачи результатов вычислений, выполненных подпрограммами, в точку вызова;
- способы возврата (передачи управления) из подпрограмм в точку вызова.
Соглашение о вызове описывает способы передачи аргументов в функцию.
Варианты:
- аргументы передаются через регистры процессора;
- аргументы передаются через стек;
- смешанные (соответственно, стандартизируется алгоритм, определяющий, что передаётся через регистры, а что — через стек или другую память):
- первые несколько аргументов передаются через регистры; остальные — через стек (небольшие аргументы) или другую память (большие аргументы);
- аргументы небольшого размера передаются через стек, большие аргументы — через другую память;
Порядок размещения аргументов в регистрах и/или стеке.
Варианты:
- слева направо или прямой порядок: аргументы размещаются в том же порядке, в котором они перечислены при вызове функции. Достоинство: машинный код соответствует коду на языке высокого уровня;
- справа налево или обратный порядок: аргументы передаются в порядке от конца к началу. Достоинство: упрощается реализация функций, принимающих произвольное число аргументов (например, printf()) (так как на вершине стека оказывается всегда первый аргумент);
Код, ответственный за очистку стека:
- код, вызывающий функцию, или вызывающая функция. Достоинство: возможность передачи в функцию произвольного числа аргументов;
- код самой функции или вызываемая функция. Достоинство: уменьшение количества инструкций, необходимых для вызова функции (инструкция для очистки стека записывается в конце кода функции и только один раз);
Конкретные инструкции, используемые для вызова и возврата. Для процессора x86, работающего в защищённом режиме, используются исключительно инструкции call и ret; при работе в стандартном режиме используются инструкции call near, call far и pushf/call far (для возврата соответственно retn, retf и iret);
Способ передачи в функцию указателя на текущий объект (this или self) в объектно-ориентированных языках.
Варианты (для процессора x86, работающего в защищённом режиме):
- как первый аргумент;
- через регистр ecx или rcx;
Код, ответственный за сохранение и восстановление содержимого регистров до и после вызова функции:
- вызывающая функция;
- вызываемая функция;
Список регистров, подлежащих сохранению/восстановлению до/после вызова функции.
Соглашение о вызове может быть описано в документации к ABI архитектуры, в документации к ОС или в документации к компилятору.
Основы ассемблера
Язык ассемблера — система обозначений, используемая для представления в удобочитаемой форме программ, записанных в машинном коде. Язык ассемблера позволяет программисту пользоваться алфавитными мнемоническими кодами операций, по своему усмотрению присваивать символические имена регистрам ЭВМ и памяти, а также задавать удобные для себя схемы адресации (например, индексную или косвенную). Кроме того, он позволяет использовать различные системы счисления (например, десятичную или шестнадцатеричную) для представления числовых констант и даёт возможность помечать строки программы метками с символическими именами с тем, чтобы к ним можно было обращаться (по именам, а не по адресам) из других частей программы (например, для передачи управления)
Набор команд:
Синтаксис языка ассемблера определяется системой команд конкретного процессора.
Типичными командами языка ассемблера являются (большинство примеров даны для Intel-синтаксиса архитектуры x86):
• Команды пересылки данных (mov и др.)
• Арифметические команды (add, sub, imul и др.)
• Логические и побитовые операции (or, and, xor, shr и др.)
• Команды управления ходом выполнения программы (jmp, loop, ret и др.)
• Команды вызова прерываний (иногда относят к командам управления): int
• Команды ввода-вывода в порты (in, out)
Некоторые команды:
mov eax, 123 ; поместить значение 123 в регистр eax
add eax, 321 ; прибавить к значению в регистре eax число 321
sub eax, 321 ; отнять от значения в регистре eax число 321
jmp loc_deadbeef ; безусловный переход на именованную метку
push eax ; положить значение регистра eax на стек
pop eax ; получить значение с вершины стека и поместить в регистр eax
call strcmp ; вызвать функцию strcmp
ret ; возврат управления в вызывающую функцию (адрес берётся с вершины стека)
Бинарные уязвимости
Под бинарными уязвимостями подразумеваются уязвимости, содержащиеся в исполняемом (скомпилированном) файле. Критичность таких уязвимостей переоценить довольно сложно. Например, если такая уязвимость будет найдена в определённой версии популярного ПО – то она распространяется на все копии этого продукта. Можно просмотреть отличия от уязвимостей веб-приложений. Уязвимость, найденная в каком-либо конкретном веб-приложении не будет распространена на все остальные.
Список типовых бинарных уязвимостей представлен ниже:
1) Переполнение буфера (стек, куча)
2) Уязвимость форматной строки
3) Целочисленное переполнение
4) Use after free
5) RCE
1. Переполнение буфера.
Переполнение буфера обычно возникает из-за неправильной работы с данными, полученными извне, и памятью, при отсутствии жесткой защиты со стороны подсистемы программирования (компилятор или интерпретатор) и операционной системы. В результате переполнения могут быть испорчены данные, расположенные следом за буфером (или перед ним).
Переполнение буфера является одним из наиболее популярных способов взлома компьютерных систем, так как большинство языков высокого уровня используют технологию стекового кадра — размещение данных в стеке процесса, смешивая данные программы с управляющими данными (в том числе адреса начала стекового кадра и адреса возврата из исполняемой функции).
Переполнение буфера может вызывать аварийное завершение или зависание программы, ведущее к отказу обслуживания (denial of service, DoS). Отдельные виды переполнений, например, переполнение в стековом кадре, позволяют злоумышленнику загрузить и выполнить произвольный машинный код от имени программы и с правами учетной записи, от которой она выполняется.
Программа, которая использует уязвимость для разрушения защиты другой программы, называется эксплойтом. Наибольшую опасность представляют эксплойты, предназначеные для получения доступа к уровню суперпользователя или, другими словами, повышения привилегий. Эксплойт переполнения буфера достигает этого путём передачи программе специально изготовленных входных данных. Такие данные переполняют выделенный буфер и изменяют данные, которые следуют за этим буфером в памяти.
Представим гипотетическую программу системного администрирования, которая исполняется с привилегиями суперпользователя — к примеру, изменение паролей пользователей. Если программа не проверяет длину введённого нового пароля, то любые данные, длина которых превышает размер выделенного для их хранения буфера, будут просто записаны поверх того, что находилось после буфера. Злоумышленник может вставить в эту область памяти инструкции на машинном языке, например, шелл-код, выполняющие любые действия с привилегиями суперпользователя — добавление и удаление учётных записей пользователей, изменение паролей, изменение или удаление файлов и т. д. Если исполнение в этой области памяти разрешено и в дальнейшем программа передаст в неё управление, система исполнит находящийся там машинный код злоумышленника.
Правильно написанные программы должны проверять длину входных данных, чтобы убедиться, что они не больше, чем выделенный буфер данных. Однако программисты часто забывают об этом. В случае если буфер расположен в стеке и стек «растёт вниз» (например в архитектуре x86), то с помощью переполнения буфера можно изменить адрес возврата выполняемой функции, так как адрес возврата расположен после буфера, выделенного выполняемой функцией. Тем самым есть возможность выполнить произвольный участок машинного кода в адресном пространстве процесса. Использовать переполнение буфера для искажения адреса возврата возможно даже если стек «растёт вверх» (в этом случае адрес возврата обычно находятся перед буфером).
Даже опытным программистам бывает трудно определить, насколько то или иное переполнение буфера может быть уязвимостью. Это требует глубоких знаний об архитектуре компьютера и о целевой программе. Было показано, что даже настолько малые переполнения, как запись одного байта за пределами буфера, могут представлять собой уязвимости.
Переполнения буфера широко распространены в программах, написанных на относительно низкоуровневых языках программирования, таких как язык ассемблера, Си и C++, которые требуют от программиста самостоятельного управления размером выделяемой памяти. Устранение ошибок переполнения буфера до сих пор является слабо автоматизированным процессом. Системы формальной верификации программ не очень эффективны при современных языках программирования.
Многие языки программирования, например, Perl, Python, Java и Ada, управляют выделением памяти автоматически, что делает ошибки, связанные с переполнением буфера, маловероятными или невозможными. Perl для избежания переполнений буфера обеспечивает автоматическое изменение размера массивов. Однако системы времени выполнения и библиотеки для таких языков всё равно могут быть подвержены переполнениям буфера, вследствие возможных внутренних ошибок в реализации этих систем проверки. В Windows доступны некоторые программные и аппаратно-программные решения, которые предотвращают выполнение кода за пределами переполненного буфера, если такое переполнение было осуществлено. Среди этих решений — DEP в Windows XP SP2.
В гарвардской архитектуре исполняемый код хранится отдельно от данных, что делает подобные атаки практически невозможными.
ПРИМЕР КОДА.
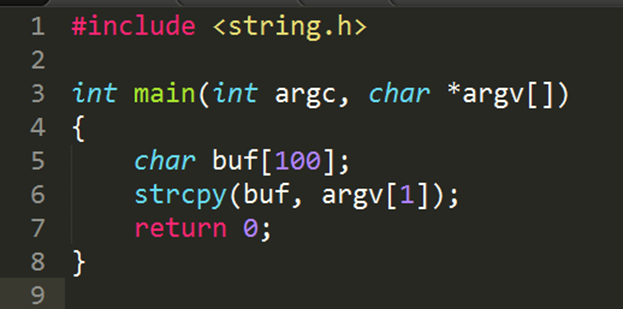
Используется небезопасная функция strcpy, которая позволяет записать больше данных, чем вмещает выделенный под них массив. Если запустить данную программу в системе Windows с аргументом, длина которого превышает 100 байт, скорее всего, работа программы будет аварийно завершена, а пользователь получит сообщение об ошибке.
Следующая программа не подвержена данной уязвимости:
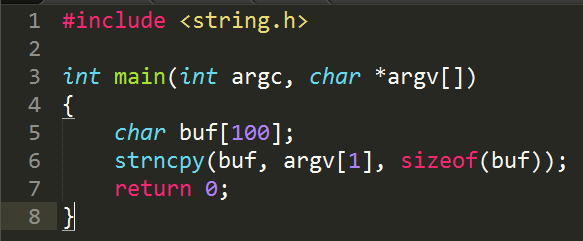
Здесь strcpy заменена на strncpy, в которой максимальное число копируемых символов ограничено размером буфера.
На схемах ниже видно, как уязвимая программа может повредить структуру стека.
Иллюстрация записи различных данных в буфер, выделенный в стеке.
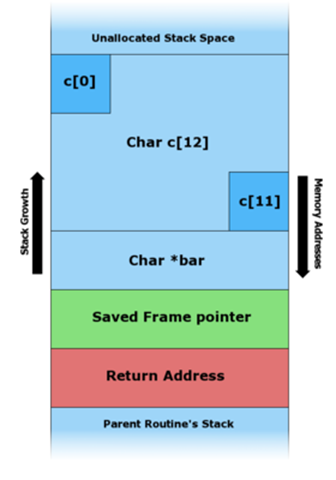
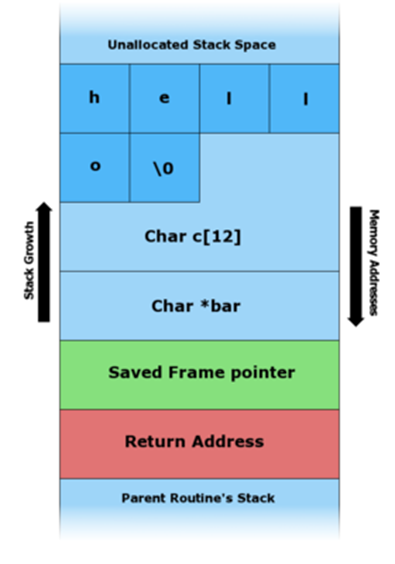
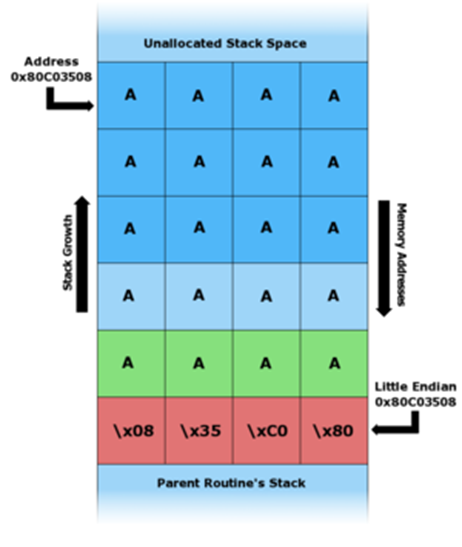
В архитектуре x86 стек растёт от больших адресов к меньшим, то есть новые данные помещаются перед теми, которые уже находятся в стеке.
Записывая данные в буфер, можно осуществить запись за его границами и изменить находящиеся там данные, в частности, изменить адрес возврата.
Если программа имеет особые привилегии (например, запущена с правами root), злоумышленник может заменить адрес возврата на адрес шелл-кода, что позволит ему исполнять команды в атакуемой системе с повышенными привилегиями.
Техники применения переполнения буфера меняются в зависимости от архитектуры, операционной системы и области памяти. Например, случай с переполнением буфера в куче (используемой для динамического выделения памяти) значительно отличается от аналогичного в стеке вызовов.
Эксплуатация в стеке
Также известно, как Stack smashing. Технически подкованный пользователь может использовать переполнение буфера в стеке, чтобы управлять программой в своих целях, следующими способами:
· перезаписывая локальную переменную, находящуюся в памяти рядом с буфером, изменяя поведение программы в свою пользу.
· перезаписывая адрес возврата в стековом кадре. Как только функция завершается, управление передаётся по указанному атакующим адресу, обычно в область памяти, к изменению которой он имел доступ.
· перезаписывая указатель на функцию или обработчик исключений, которые впоследствии получат управление.
· перезаписывая параметр из другого стекового кадра или нелокальный адрес, на который указывается в текущем контексте.
Если адрес пользовательских данных неизвестен, но он хранится в регистре, можно применить метод «trampolining» (с англ. — «прыжки на батуте»): адрес возврата может быть перезаписан адресом опкода, который передаст управление в область памяти с пользовательскими данными. Если адрес хранится в регистре R, то переход к команде, передающей управление по этому адресу (например, call R), вызовет исполнение заданного пользователем кода. Адреса подходящих опкодов или байтов памяти могут быть найдены в DLL или в самом исполняемом файле. Однако адреса обычно не могут содержать нулевых символов, а местонахождения этих опкодов меняются в зависимости от приложения и операционной системы. Metasploit Project, например, хранил базу данных подходящих опкодов для систем Windows (на данный момент она недоступна).
Переполнение буфера в стеке не нужно путать с переполнением стека.
Также стоит отметить, что такие уязвимости обычно находят с помощью техники fuzz testing.
Эксплуатация в куче
Переполнение буфера в области данных кучи называется переполнением кучи и эксплуатируется иным способом, чем переполнение буфера в стеке. Память в куче выделяется приложением динамически во время выполнения и обычно содержит программные данные. Эксплуатация производится путём порчи этих данных особыми способами, чтобы заставить приложение перезаписать внутренние структуры, такие как указатели в связных списках. Обычная техника эксплойта для переполнения буфера кучи — перезапись ссылок динамической памяти (например, метаданных функции malloc) и использование полученного изменённого указателя для перезаписи указателя на функцию программы.
Уязвимость в продукте GDI+ компании Microsoft, возникающая при обработке изображений формата JPEG — пример опасности, которую может представлять переполнение буфера в куче.
Это теория. В следующих уроках мы передём к практике.











Очень круто написано и все понятно и интересно .Спасибо большое за бесплатную статью
Благодарю за статью, полезно.