Гидра. Всмысле, GHIDRA. Ищем клады в коде. Краткий обзор дизасемблера от NSA

Гидра? А? Кто сказал Гидра?
Я сказал GHIDRA. Это фреймворк по SRE (software reverse engineering), или по-русски, реверсу ПО от NSA. Да-да, АНБ США подарило нам такую возможность.
В этой статье мы разберём процесс установки, первичной настройки, посмотрим как загружать проекты и рассмотрим использование на примере простого “crackme” CTF.
Я не считаю себя экспертом ни по реверсу, в целом, ни, тем более по этому инструменту, в частности. Мы кратко пробежимся по основным достоинствам инструмента и посмотрим на его недостатки. Если вам нужен курс по GHIDRA, можете посмотреть на YouTube, вроде бы само АНБ сделало некоторый короткий гайд для этого замечательного инструмента.
Для использования этого инструмента тебе потребуются хотя бы рудиментарные познаня ассемблера и архитектуры ПК.
Что такое GHIDRA?
Это платформа для реверса или, по просту, разборки, кода от АНБ. Включается в себя дизассмеблер под разные архитектуры, а также декомплиятор (что радует, потому что в том же популярном IDA декомпилятор есть не под всё). С лёгкой руки АНБ этот инструмент стал доступен широкой аудитории.
По сути это дизассмеблер со своими фичами и багами, но его делали за деньги, поэтому качество всё же получше, чем у полностью open-source решений.
Подробную информация можно почитать на официальном сайте проекта (с русских IP не пускает, используйте VPN или прокси) – ссылка.
Там же его можно и скачать, что мы и сделаем.
Установка
GHIDRA написан на JAVA, поэтому требует установки JDK 11. Этот компонент можно скачать вот отсюда ссылка.
Инсталяции не требуется, просто распакуйте архив в любую удобную для вас директорию.
Запуск
Если вы всё сделали верно, то для запуска вам нужно всего лишь запустить файл “ghidraRun.bat”. После этого вы увидите вот это:

Это меню загрузки, просто подождём немного и оно поменяется на:
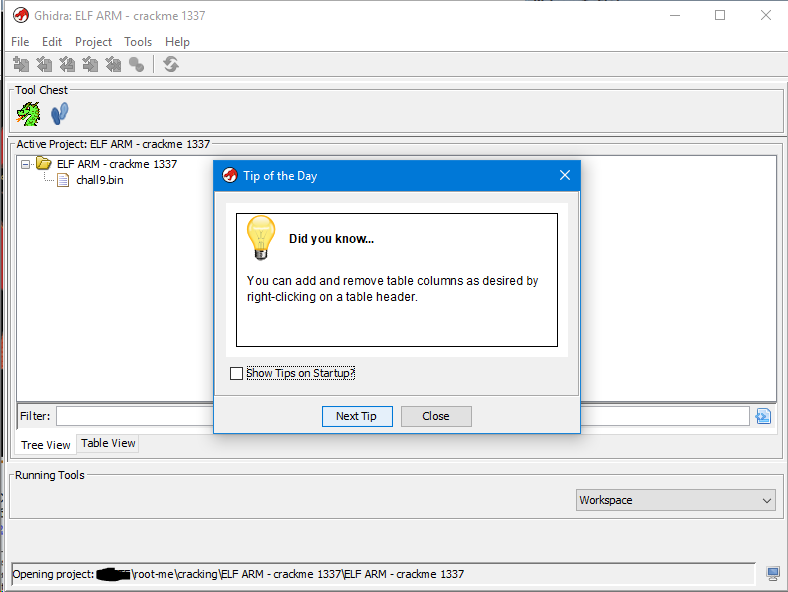
Здесь вы видите небольшой ежедневный совет (их можно отключить, просто убрав галочку в чек-боксе), и лаунчер с проектами.
Одна из приятных фич это то, что можно создать проект и в данном проекте создать папки под каждый бинарный файл, таким образом удобно ориентироваться между небольшими бинарями. Это может быть полезно при исследований какого-то семейства связанных файлов (проишвка, большое приложение и др.)
Создание проекта
Давайте попробуем создать новый проект.
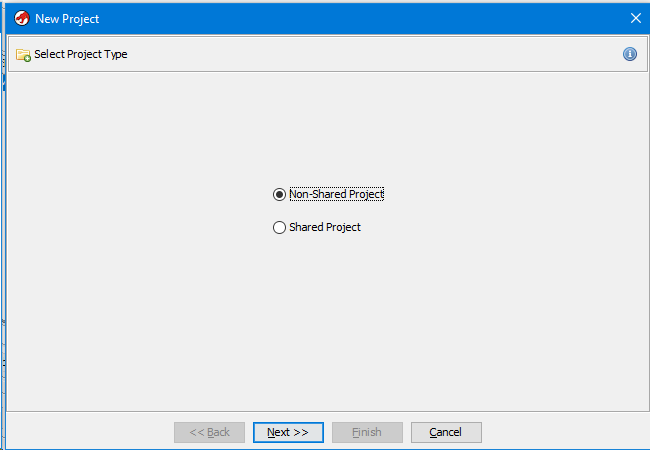
В верхнем меню выбираем “File->New Project”. После появится окно выбора типа проекта, он может быть локальный или удалённый (базироваться на каком-то сервере). Тоже стоит отметить данную фичу. Если вы работаете над проектом группой реверс-инженеров это крайне удобно.
Мы создадим локальный проект, то есть нам надо выбрать “Non-Shared Project”.
Далее нам надо выбрать где будет хранится проект и его указать имя.
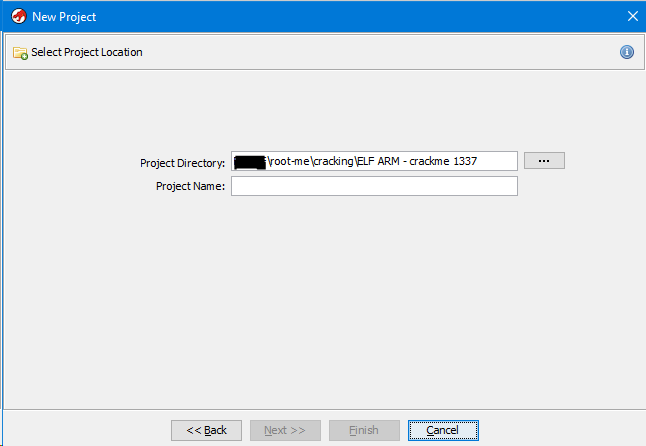
Здесь комментировать особо нечего. После ввода имени и нажатия кнопки “Next>>” создаётся новый проект и ваше меню теперь будет выглядит примерно так.
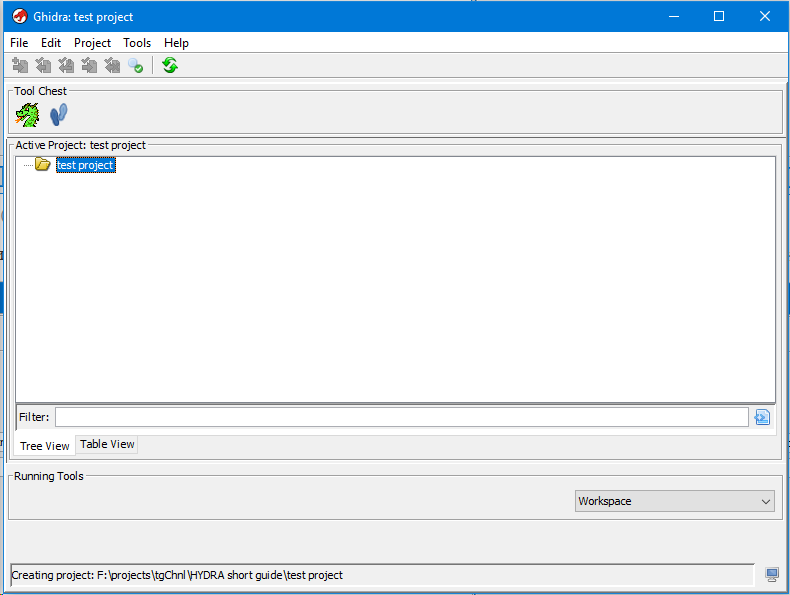
Отлично проект создан, но сейчас он пустой. Чтобы добавить какой-нибудь бинарник на исследование его можно просто перетащить в данное окно.
Для примера возьмём один из тасков категории “Reverse” с UTCTF’a.
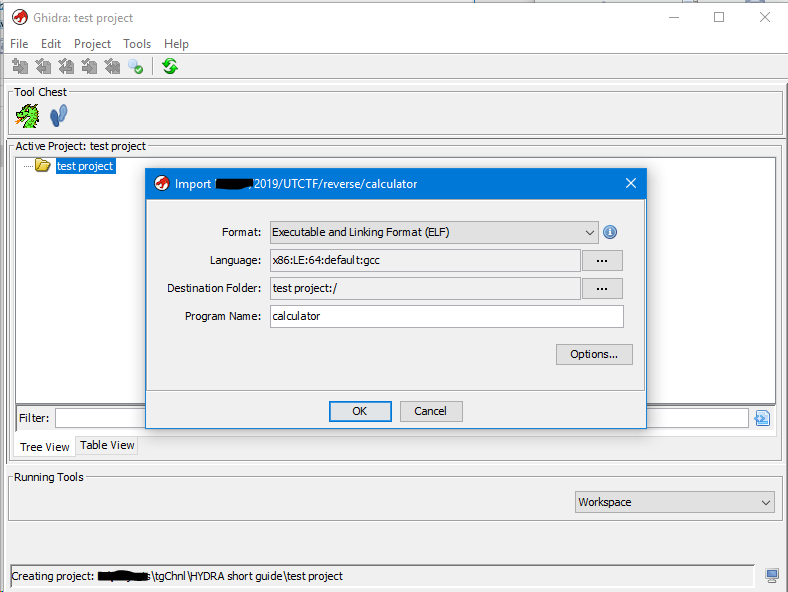
Видим, что при загрузке бинаря были определены следующие параметры:
- Формат
- Язык (хотя пишется название микропроцессорной архитектуры)
- Папка назначения в проекте
- Имя бинарника
Нажимаем “OK” и данный файл добавляется в наш проект. После успешного импорта файла будет выведен небольшой отчёт по импорту в таком формате.
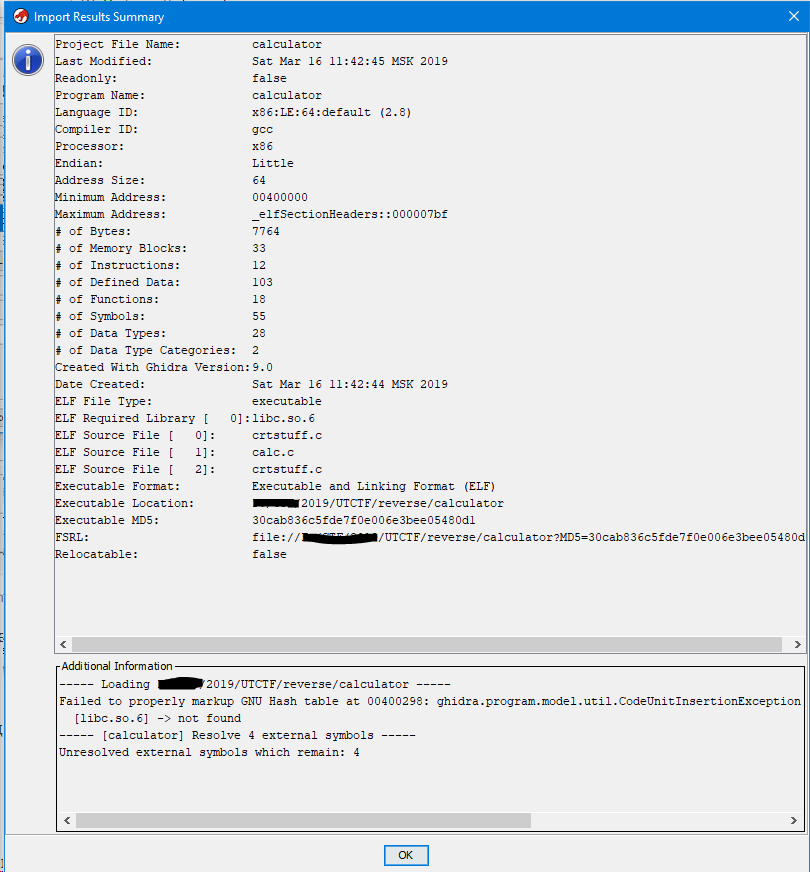
Здесь приведена расширенная общая информация и информация импорта.
Теперь наш проект выглядит так.
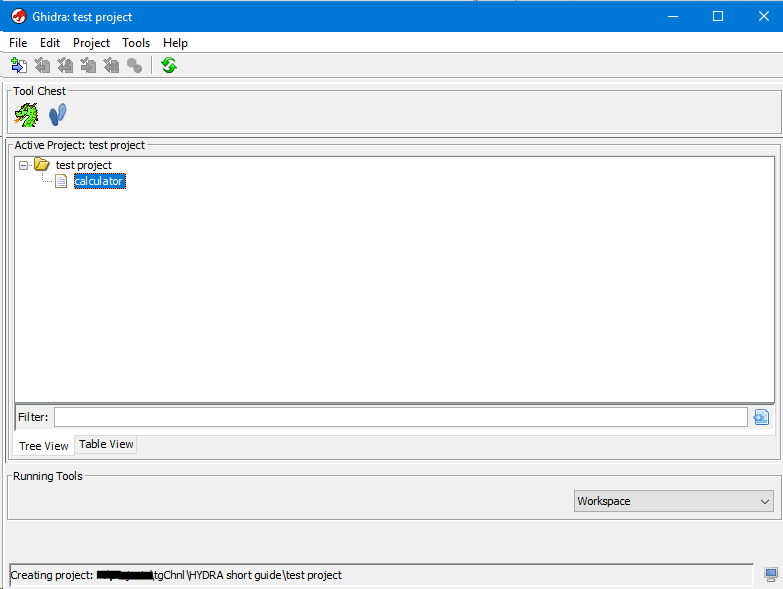
Для того, чтобы открыть бинарный файл в GHIDRA и начать его исследование можно просто выбрать интересующий файл и кликнуть по нему дважды. После запуститься сам дизассемблер и предложит вам провести полный анализ файла.
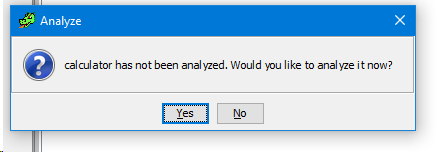
Соглашаемся и выбираем какие опции анализа мы хотим включить или выключить.
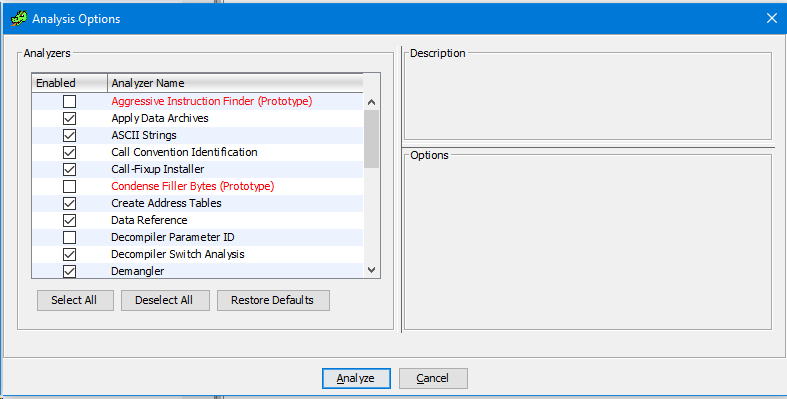
После нажимаем “Analyze” и ждём окончание анализа. Наблюдать за процессом анализа можно в правом нижнем углу экране, где есть панель текущего состояние того или иного процесса.

Отлично, теперь перед нам проанализированный бинарник и можно начинать работы по его исследованию.
Теперь, когда мы разобрались с загрузкой бинарника и его авто-анализом рассмотрим настройку самого CodeBrowser’a в котором и осуществляется большая часть работы.
Настройка CodeBrowser’a
Для настройки используйте меню “Edit->Tool options”. Там вы найдете следующее крупное меню.
Первоначально рекомендую настроить шрифты и цвета, т.к. стандартные не очень приятные глазу (хотя каждому своё). Но это настройки только для обычного обозревателя. Для декомпилятора есть отдельные настройки, которые можно найти здесь.
Стоит отметить, что в GHIRDA не так много хот-кеев по умолчания, а те которые есть не на совсем привычных местах (если вы долго использовали IDA, то это будет больно). Для решения это проблемы вы можете сделать ребиндинг с помощью соответственного меню в настройках.
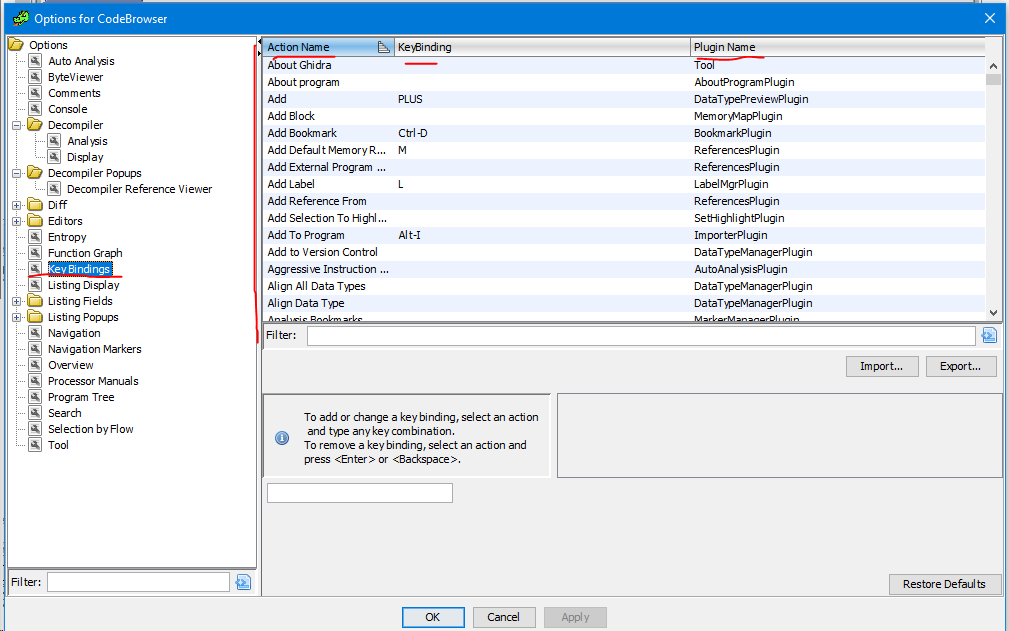
Здесь уже нужно будет покопаться и настроить всё под себя (в принципе это нужно делать всегда, вы ведь настраиваете для личного удобства в использовании).
Стандартное меню настройки достаточно неплохое и гибкое, но всё же некоторые моменты у меня не получилось настроить, например подсвечивание всех вхождений выделенного имени в коде, что очень неудобно при анализе более-менее большой функции.
Рассмотрим некоторые команды.
Базовые команды
Для вызова различных отображений той или иной информации, содержащейся в файле вы можете использовать опцию “Windows”.
Например окно “Defined Strings”, будет содержать все строки, которые были найдены автоматически в бинарнике.
Не очень привычное отображения, конечно.
В окне “Script Manager” вы можете найти более 200 встроенных скриптов для различных задач, это достаточно интересное решение, сразу встраивать скрипты, которые по сути должен создавать пользователь под свои задачи.
Не знаю, на сколько они применимы, пока подробно не изучал, но в целом достойно похвалы такое решение, особенно если там найдутся скрипты для решения популярных проблем обратной разработки.
Стоит ещё отметить наличие меню с выбором различных анализов над файлом.
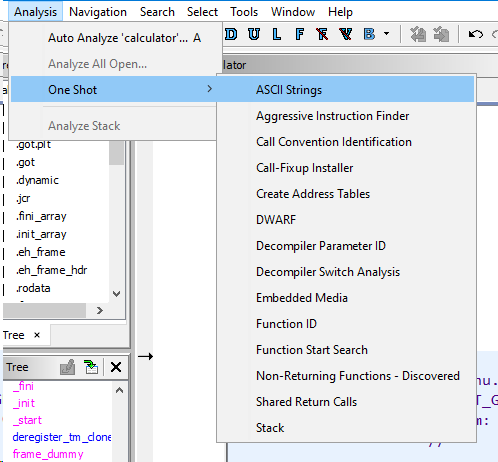
Это может быть удобно при анализе прошивки, т.к. их загрузка обычно происходит не совсем просто.
Итоги
Если не вдаваться в детали, по функционалу с IDA различий не особо много, для большей части задач подойдёт. Но есть один нюанс, в том что различий нет с платной версией IDA, которую не все могут себе позволить. А GHIDRA полностью бесплатная.
Есть неудобства для тех, кто привык к интерфейсу других инструментов, но в целом задачи свои GHIDRA выполняет “на ура”.
Особенно радует декомпилятор под другие архитектуры.
Можно много ещё чего поизучать в устройстве данного инструмента, посмотреть на поддержку скриптового языка, предоставляемого API и прочее, но на это уйдёт куда больше времени и, думаю, это будет полезно проделать самостоятельно. Если у тебя всё получилось, ты встал на верный путь реверсера.
Для тех же, кто хочет подробнее ознакомится с этой замечательной тулзой отт АНБ, даю ссылки:
- Официальная страница на сайте АНБ США
- Проект на Github
- Первый обзор в журнале «Хакер»
- Отличный канал на YouTube с разбором программ в Ghidra
Погоняем Гидру?
Шаг 1. crackme
Для наших опытов возьмём простую «крякми» (crackme) программку. Я просто зашел на сайт crackmes.one, указал в поиске уровень сложности = 2-3 («простой» и «средний»), исходный язык программы = «C/C++» и платформу = «Multiplatform», как на скриншоте ниже:
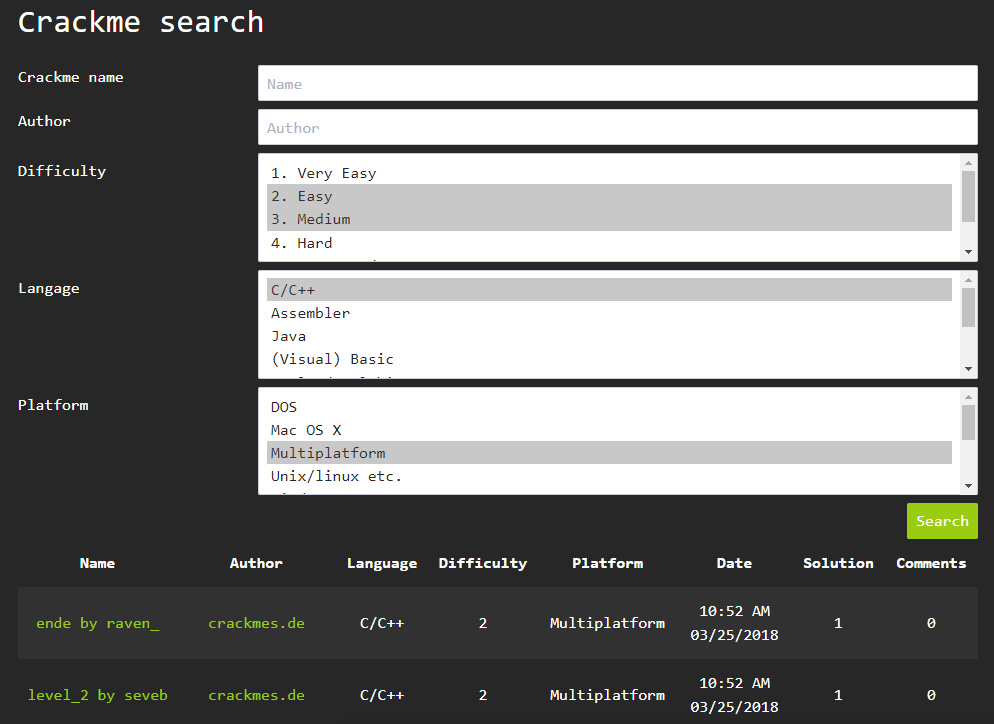
Поиск выдал 2 результата (внизу зеленым шрифтом). Первая крякми оказалась 16-битной и не запустилась на моей Win10 64-bit, а вот вторая (level_2 by seveb) подошла. Вы можете скачать ее по этой ссылке.
Скачиваем и распаковываем крякми; пароль на архив, как указано на сайте, — crackmes.de. В архиве находим два каталога, соответствующие ОС Linux и Windows. На своей машине я перехожу в каталог Windows и встречаю в нем единственную «экзешку» — level_2.exe. Давайте запустим и посмотрим, чего она хочет:

Похоже, облом! При запуске программа ничего не выводит. Пробуем запустить еще раз, передав ей произвольную строку в качестве параметра (вдруг, она ждет ключ?) — и вновь ничего… Но не стоит отчаиваться. Давайте предположим, что и параметры запуска нам тоже предстоит выяснить в качестве задания! Пора расчехлять наш «швейцарский нож» — Гидру.
Шаг 2. Создание проекта в Гидре и предварительный анализ
Предположим, что Гидра у тебя уже установлена. Если еще нет, то все просто.
Установка Ghidra
Запускаем Гидру и в открывшемся Менеджере проектов сразу создаем новый проект; я дал ему имя crackme3 (т.е.проекты crackme и crackme2 уже у меня созданы). Проект — это, по сути, каталог файлов, в него можно добавлять любые файлы для изучения (exe, dll и т.д.). Мы сразу же добавим наш level_2.exe (File | Import или просто клавиша I):
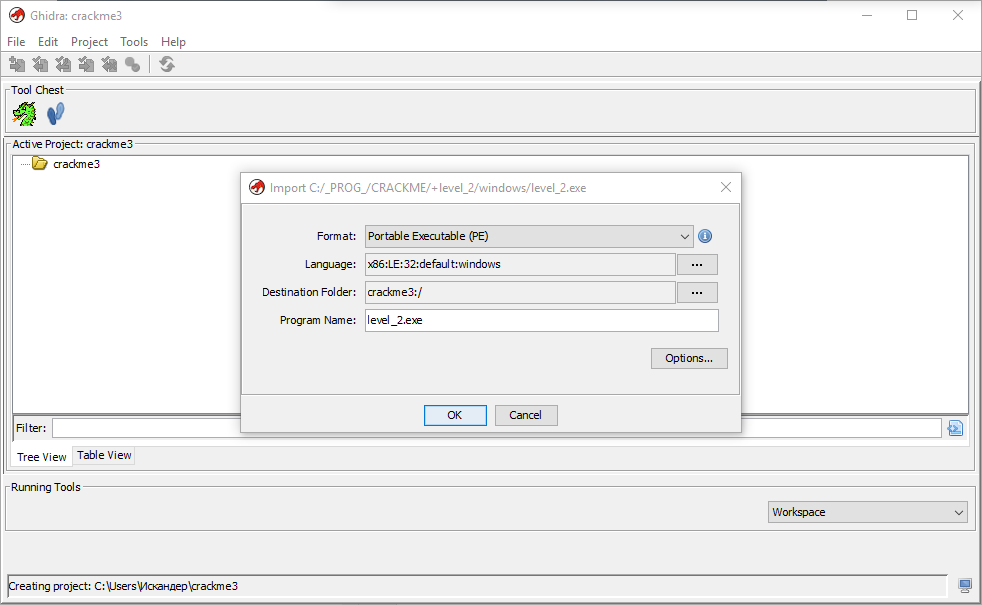
Видим, что уже до импорта Гидра определила нашу подопытную крякми как 32-разрядный PE (portable executable) для ОС Win32 и платформы x86. После импорта наш ждет еще больше информации:
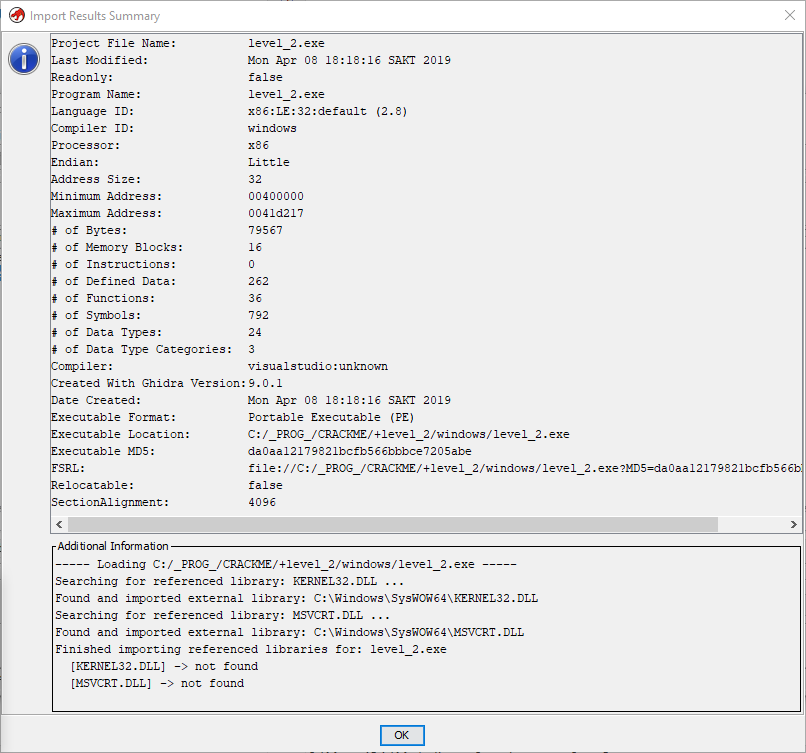
Здесь, кроме вышеуказанной разрядности, нас может еще заинтересовать порядок байтов (endianness), который в нашем случае — Little (от младшего к старшему байту), что и следовало ожидать для «интеловской» 86-й платформы.
С предварительным анализом мы закончили.
Шаг 3. Выполнение автоматического анализа
Время запустить полный автоматический анализ программы в Гидре. Это делается двойным кликом на соответствующем файле (level_2.exe). Имея модульную структуру, Гидра обеспечивает всю свою основную функциональность при помощи системы плагинов, которые можно добавлять / отключать или самостоятельно разрабатывать. Так же и с анализом — каждый плагин отвечает за свой вид анализа. Поэтому сначала перед нами открывается вот такое окошко, в котором можно выбрать интересующие виды анализа:
Окно настройки анализа
Для наших целей имеет смысл оставить настройки по умолчанию и запустить анализ. Сам анализ выполняется довольно быстро (у меня занял около 7 секунд), хотя пользователи на форумах сетуют на то, что для больших проектов Гидра проигрывает в скорости IDA Pro. Возможно, это и так, но для небольших файлов эта разница несущественна.
Итак, анализ завершен. Его результаты отображены в окне браузера кода (Code Browser):
Это окно является основным для работы в Гидре, поэтому следует изучить его более внимательно.
Обзор интерфейса браузера кода
Шаг 4. Изучение алгоритма программы — функция main()
Что ж, приступим к непосредственному анализу нашей крякми-программки. Начинать следует в большинстве случаев с поиска точки входа программы, т.е. основной функции, которая вызывается при ее запуске. Зная, что наша крякми написана на C/C++, догадываемся, что имя основной функции будет main() или что-то в этом духе 🙂 Сказано-сделано. Вводим «main» в фильтр Дерева символов (в левой панели) и видим функцию _main() в секции Functions. Переходим на нее кликом мыши.
Обзор функции main() и переименование непонятных функций
В листинге дизассемблера сразу же отображается соответствующий участок кода, а справа видим декомпилированный C-код этой функции. Здесь стоит отметить еще одну удобную фишку Гидры — синхронизацию выделения: при выделении мышью диапазона ASM-команд выделяется и соответствующий участок кода в декомпиляторе и наоборот. Кроме того, если открыто окно просмотра памяти, выделение синхронизируется и с памятью. Как говорится, все гениальное просто!
Сразу отмечу важную особенность работы в Гидре (в отличие, скажем, от работы в IDA). Работа в Гидре ориентирована, в первую очередь, именно на анализ декомпилированного кода. По этой причине создатели Гидры (мы помним — речь о шпионах из АНБ :)) уделили большое внимание качеству декомпиляции и удобству работы с кодом. В частности, перейти к определению функций, переменных и секций памяти можно просто двойным кликом в коде. Также любую переменную и функцию можно тут же переименовать, что весьма удобно, так как дефолтные имена не несут в себе смысла и могут сбить с толку. Как ты увидишь далее, этим механизмом мы будем часто пользоваться.
Итак, перед нами функция main(), которую Гидра «препарировала» следующим образом:
Листинг main()
Вроде бы с виду все нормально — определения переменных, стандартные C-шные типы, условия, циклы, вызовы функций. Но взглянув на код внимательнее, замечаем, что имена некоторых функций почему-то не определились и заменены псевдофункцией _text() (в окне декомпилятора — .text()). Давайте сразу начнем определения, что это за функции.
Перейдя двойным кликом в тело первого вызова
_Dest = (char *)_text(0x100,1);
видим, что это — всего лишь функция-обертка вокруг стандартной функции calloc(), служащей для выделения памяти под данные. Поэтому давайте просто переименуем эту функцию в calloc2(). Установив курсор на заголовке функции, вызываем контекстное меню и выбираем Rename function (горячая клавиша — L) и вводим в открывшееся поле новое название:
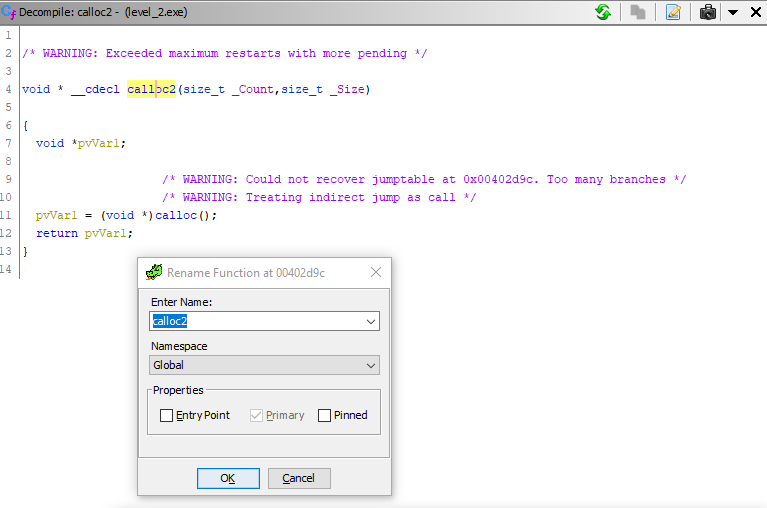
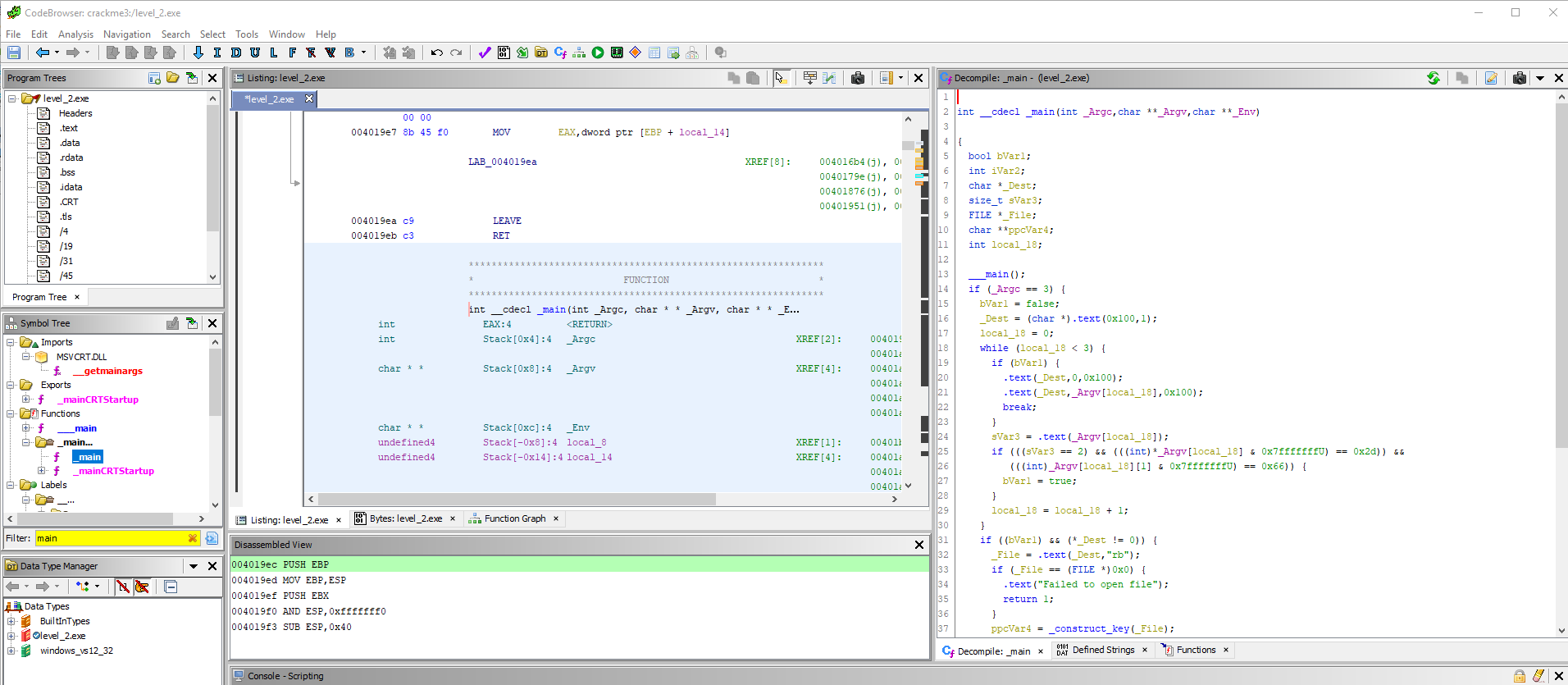
Видим, что функция тут же переименовалась. Возвращаемся назад в тело main() (кнопка Back в тулбаре или Alt + <–) и видим, что здесь вместо загадочного _text() уже стоит calloc2(). Отлично!
То же самое проделываем и со всеми остальными функциями-обертками: поочередно переходим в их определение, смотрим, что они делают, переименовываем (я к стандартным названиям C-функций добавлял индекс 2) и возвращаемся назад в основную функцию.
Постигаем код функции main()
Ладно, с непонятными функциями разобрались. Начинаем изучать код основной функции. Пропуская объявления переменных, видим, что функция возвращает значение переменной iVar2, которое равно нулю (признак успеха функции) только в случае если выполняется условие, заданное строкой
if (_Argc == 3) { ... }
_Argc — это количество параметров (аргументов) командной строки, передаваемых в main(). То есть, наша программа «кушает» 2 аргумента (первый аргумент, мы помним, — это всегда путь к исполняемому файлу).
ОК, идем дальше. Вот здесь мы создаем C-строку (массив char) из 256 символов:
char *_Dest;
_Dest = (char *)calloc2(0x100,1); // эквивалент new char[256] в C++
Дальше у нас цикл из 3 итераций. В нем сначала проверяем, установлен ли флаг bVar1 и если да — копируем следующий аргумент командной строки (строку) в _Dest:
while (i < 3) {
/* цикл по аргументам ком. строки */
if (bVar1) {
/* инициализировать массив */
memset2(_Dest,0,0x100);
/* скопировать строку в _Dest и прервать цикл */
strncpy2(_Dest,_Argv[i],0x100);
break;
}
...
}
Этот флаг устанавливается при анализе следующего аргумента:
n_strlen = strlen2(_Argv[i]);
if (((n_strlen == 2) && (((int)*_Argv[i] & 0x7fffffffU) == 0x2d)) &&
(((int)_Argv[i][1] & 0x7fffffffU) == 0x66)) {
bVar1 = true;
}
Первая строка вычисляет длину этого аргумента. Далее условие проверяет, что длина аргумента должна равняться 2, предпоследний символ == “-” и последний символ == «f». Обрати внимание, как декомпилятор «перевел» извлечение символов из строки при помощи байтовой маски.
Десятичные значения чисел, а заодно и соответствующие ASCII-символы можно подсмотреть, удерживая курсор над соответствующим шестнадцатеричным литералом. Отображение ASCII не всегда работает (?), поэтому рекомендую глядеть ASCII таблицу в Интернете. Также можно прямо в Гидре конвертировать скаляры из любой системы счисления в любую другую (через контекстное меню –> Convert), в этом случае данное число везде будет отображаться в выбранной системе счисления (в дизассемблере и в декомпиляторе); но лично я предпочитаю в коде оставлять hex’ы для стройности работы, т.к. адреса памяти, смещения и т.д. везде задаются именно hex’ами.
После цикла идет этот код:
if ((bVar1) && (*_Dest != 0)) {
/* если получили аргументы 1) "-f" и 2) строку -
открыть указанный файл для чтения в двоичном формате */
_File = fopen2(_Dest,"rb");
if (_File == (FILE *)0x0) {
/* вернуть 1 при ошибке чтения */
perror2("Failed to open file");
return 1;
}
...
}
Здесь я сразу добавил комментарии. Проверяем правильность аргументов (“-f путь_к_файлу”) и открываем соответствующий файл (2-й переданный аргумент, который мы скопировали в _Dest). Файл будет читаться в двоичном формате, на что указывает параметр «rb» функции fopen(). При ошибке чтения (например, файл недоступен) выводится сообщение об ошибке в поток stderror и программа завершается с кодом 1.
Далее — самое интересное:
/* !!! ПРОВЕРКА КЛЮЧА В ФАЙЛЕ !!! */
ppcVar3 = _construct_key(_File);
if (ppcVar3 == (char **)0x0) {
/* если получили пустой массив, вывести "Nope" */
puts2("Nope.");
_free_key((void **)0x0);
}
else {
/* массив не пуст - вывести ключ и освободить память */
printf2("%s%s%s%s\n",*ppcVar3 + 0x10d,*ppcVar3 + 0x219,*ppcVar3 + 0x325,*ppcVar3 + 0x431);
_free_key(ppcVar3);
}
fclose2(_File);
Дескриптор открытого файла (_File) передается в функцию _construct_key(), которая, очевидно, и производит проверку искомого ключа. Эта функция возвращает двумерный массив байтов (char**), который сохраняется в переменную ppcVar3. Если массив оказывается пуст, в консоль выводится лаконичное «Nope» (т.е. по-нашему «Не-а!») и память освобождается. В противном случае (если массив не пуст) — выводится по-видимому верный ключ и память также освобождается. В конце функции закрывается дескриптор файла, освобождается память и возвращается значение iVar2.
Итак, теперь мы поняли, что нам необходимо:
1) создать двоичный файл с верным ключом;
2) передать его путь в крякми после аргумента “-f”
Шаг 5 — Обзор функции _construct_key()
Давайте сразу посмотрим на полный листинг этой функции:
Листинг функции _construct_key()
С этой функцией мы поступим так же, как и ранее с main() — для начала пройдемся по «завуалированным» вызовам функций. Как и ожидаось, все эти функции — из стандартных библиотек C. Описывать заново процедуру переименования функций не буду — вернись к первой части статьи, если нужно. В результате переименования «нашлись» следующие стандартные функции:
- fread()
- strncmp()
- strlen()
- ftell()
- fseek()
- puts()
Соответствующие функции-обертки в нашем коде (те, что декомпилятор нагло прятал за словом _text) мы переименовали в эти, добавив индекс 2 (чтобы не возникало путаницы с оригинальными C-функциями). Почти все эти функции служат для работы с файловыми потоками. Оно и не удивительно — достаточно беглого взгляда на код, чтобы понять, что здесь производится последовательное чтение данных из файла (дескриптор которого передается в функцию в качестве единственного параметра) и сравнение прочитанных данных с неким двумерным массивом байтов local_14.
Давайте предположим, что этот массив содержит данные для проверки ключа. Назовем его, скажем, key_array. Поскольку Гидра позволяет переименовывать не только функции, но и переменные, воспользуемся этим и переименуем непонятный local_14 в более понятный key_array. Делается это так же, как и для функций: через меню правой клавиши мыши (Rename local) или клавишей L с клавиатуры.
Итак, сразу же за объявлением локальных переменных вызывается некая функция _prepare_key():
key_array = (char **)__prepare_key();
if (key_array == (char **)0x0) {
key_array = (char **)0x0;
}
К _prepare_key() мы еще вернемся, это уже 3-й уровень вложенности в нашей иерархии вызовов: main() -> _construct_key() -> _prepare_key(). Пока же примем, что она создает и как-то инициализирует этот «проверочный» двумерный массив. И только в случае если этот массив не пуст, функция продолжает свою работу, о чем свидетельствует блок else сразу же после приведенного условия.
Далее программа читает первые 4 байта из файла и сравнивает с соответствующим участком массива key_array. (Код ниже — уже после произведенных переименований, в т.ч. переменную local_19 я переименовал в first_4bytes.)
first_4bytes = 0;
/* прочитать первые 4 байта из файла */
fread2(&first_4bytes,1,4,param_1);
/* сравнить с key_array[1][0...3] */
iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4);
if (iVar1 == 0) { ... }
Таким образом, дальнейшее выполнение происходит только в случае совпадения первых 4 байтов (запомним это). Дальше читаем 2 2-байтных блока из файла (причем в роли буфера для записи данных используется тот же key_array):
fread2(key_array[1] + 4,2,1,param_1);
fread2(key_array[1] + 6,2,1,param_1);
И вновь — дальше функция работает только в случае истинности очередного условия:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
// выполняем дальше ...
}
Нетрудно увидеть, что первый из прочитанных выше 2-байтных блока должно быть числом 5, а второй — числом 4 (тип данных short как раз занимает 2 байта на 32-разрядных платформах).
Дальше — вот это:
local_30[0] = *key_array; // т.е. key_array[0]
local_30[1] = *key_array + 0x10c;
local_30[2] = *key_array + 0x218;
local_30[3] = *key_array + 0x324;
local_20 = *key_array + 0x430;
Здесь мы видим, что в массив local_30 (объявленный как char *local_30 [4]) заносятся смещения указателя key_array. То есть local_30 — это массив строк-маркеров, в который наверняка будут читаться данные из файла. По этому допущению я переименовал local_30 в markers. В этом участке кода немного подозрительной кажется только последняя строка, где присвоение последнего смещения (по индексу 0x430, т.е. 1072) выполняется не очередному элементу markers, а отдельной переменной local_20 (char*). Но с этим мы еще разберемся, а пока — давайте двигаться дальше!
Дальше нас ожидает цикл:
i = 0; // local_10 переименовал в i
while (i < 5) {
// ...
i = i + 1;
}
Т.е. всего 5 итераций от 0 до 4 включительно. В цикле сразу начинается чтение из файла и проверка на соответствие нашему массиву markers:
char c_marker = 0; // переименовал из local_35
/* прочитать след. байт из файла */
fread2(&c_marker, 1, 1, param_1);
if (*markers[i] != c_marker) {
/* здесь и далее - вернуть пустой массив при ошибке */
_free_key(key_array);
return (char **)0x0;
}
То есть читается следующий байт из файла в переменную c_marker (в оригинальном декомпилированном коде — local_35) и проверяется на соответствие первому символу i-го элемента markers. В случае несоответствия массив key_array обнуляется и возвращается пустой двойной указатель. Далее по коду мы видим, что такое проделывается всякий раз при несовпадении прочитанных данных с проверочными.
Но тут, как говорится, «зарыта собака». Давайте внимательнее посмотрим на этот цикл. В нем 5 итераций, как мы выяснили. Это можно при желании проверить, взглянув на ассемблерный код:


Действительно, команда CMP сравнивает значение переменной local_10 (у нас это уже i) с числом 4 и если значение меньше или равно 4 (команда JLE) производится переход к метке LAB_004017eb, т.е. начало тела цикла. Т.е. условие будет соблюдаться для i = 0, 1, 2, 3 и 4 — всего 5 итераций! Все бы хорошо, но markers также индексируется по этой переменной в цикле, а ведь этот массив у нас объявлен только с 4 элементами:
char *markers [4];
Значит, кто-то кого-то явно обмануть пытается 🙂 Помните, я сказал, что эта строка наводит сомнения?
local_20 = *key_array + 0x430;
Еще как! Просто посмотрите на весь листинг функции и попробуйте отыскать еще хоть одну ссылку на переменную local_20. Ее нет! Отсюда делаем вывод: это смещение должно также сохраняться в массив markers, а сам массив должен содержать 5 элементов. Давайте исправим это. Переходим к объявлению переменной, жмем Ctrl + L (Retype variable) и смело меняем размер массива на 5:
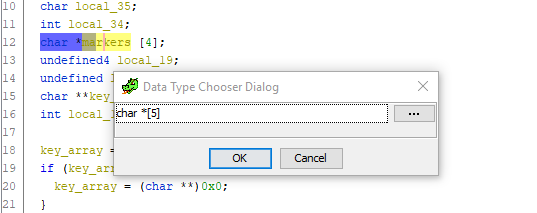
Готово. Скроллим ниже до кода присвоения смещений указателя элементам markers, и — о чудо! — исчезает непонятная лишняя переменная и все становится на свои места:
markers[0] = *key_array;
markers[1] = *key_array + 0x10c;
markers[2] = *key_array + 0x218;
markers[3] = *key_array + 0x324;
markers[4] = *key_array + 0x430; // убежавшее было присвоение... мы поймали тебя!
Возвращаемся к нашему циклу while (в исходном коде это, скорее всего, будет for, но нас это не волнует). Далее опять читается байт из файла и проверяется его значение:
byte n_strlen1 = 0; // переименован из local_36
/* прочитать след. байт из файла */
fread2(&n_strlen1,1,1,param_1);
if (n_strlen1 == 0) {
/* значение не должно быть нулевым */
_free_key(key_array);
return (char **)0x0;
}
ОК, этот n_strlen1 должен быть ненулевым. Почему? Сейчас увидишь, а заодно и поймешь, почему я присвоил этой переменной такое имя:
/* записываем значение n_strlen1) в (markers[i] + 0x104) */
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1;
/* прочитать из файла (n_strlen1) байт (--> некая строка?) */
fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1);
n_strlen2 = strlen2(markers[i] + 1); // переименован из sVar2
if (n_strlen2 != *(size_t *)(markers[i] + 0x104)) {
/* длина прочитанной строки (n_strlen2) должна == n_strlen1 */
_free_key(key_array);
return (char **)0x0;
}
Я добавил комментарии, по которым должно быть все понятно. Из файла читается n_strlen1 байтов и сохраняется как последовательность символов (т.е. строка) в массив markers[i] — то есть после соответствующего «стоп-символа», которые там уже записаны из key_array. Сохранение значения n_strlen1 в markers[i] по смещению 0x104 (260) здесь не играет никакой роли (см. первую строку в коде выше). По факту этот код можно оптимизировать следующим образом (и наверняка так это и есть в исходном коде):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1);
n_strlen2 = strlen2(markers[i] + 1);
if (n_strlen2 != (size_t) n_strlen1) { ... }
Также проводится проверка того, что длина прочитанной строки равна n_strlen1. Это может показаться излишним, с учетом что данный параметр передавался в функцию fread, но fread читает не более столько-то указанных байтов и может прочитать меньше, чем указано, например, в случае встречи маркера конца файла (EOF). То есть все строго: в файле указывается длина строки (в байтах), затем идет сама строка — и так ровно 5 раз. Но мы забегаем вперед.
Далее вод этот код (который я также сразу прокомментировал):
uint n_pos = 0; // переименован из local_3c
/* прочитать след. байт из файла */
fread2(&n_pos,1,1,param_1);
/* увеличить на 7 */
n_pos = n_pos + 7;
/* получить позицию файлового курсора */
uint n_filepos = ftell2(param_1); // переименован из uVar3
if (n_pos < n_filepos) {
/* n_pos должна быть >= n_filepos */
_free_key(key_array);
return (char **)0x0;
}
Здесь все еще проще: берем следующий байт из файла, прибавляем 7 и полученное значение сравниваем с текущей позицией курсора в файловом потоке, полученным функцией ftell(). Значение n_pos должно быть не меньше позиции курсора (т.е. смещения в байтах от начала файла).
Завершающая строка в цикле:
fseek2(param_1,n_pos,0);
Т.е. переставляем курсор файла (от начала) на позицию, указанную n_pos функцией fseek(). ОК, все эти операции в цикле мы проделываем 5 раз. Завершается же функция _construct_key() следующим кодом:
int i_lastmarker = 0; // переименован из local_34
/* прочитать последние 4 байт из файла (int32) */
fread2(&i_lastmarker,4,1,param_1);
if (*(int *)(*key_array + 0x53c) == i_lastmarker) {
/* это число должно == key_array[0][1340]
...тогда все ОК :) */
puts2("Markers seem to still exist");
}
else {
_free_key(key_array);
key_array = (char **)0x0;
}
Таким образом, последним блоком данных в файле должно быть 4-байтовое целочисленное значение и оно должно равняться значению в key_array[0][1340]. В этом случае нас ждет поздравительное сообщение в консоли. А в противном случае — все так же возвращается пустой массив без всяких похвал 🙂
Шаг 6 — Обзор функции __prepare_key()
У нас осталась только одна неразобранная функция — __prepare_key(). Мы уже догадались, что именно в ней формируется проверочные данные в виде массива key_array, который затем используется в функции _construct_key() для проверки данных из файла. Осталось выяснить, какие именно там данные!
Я не буду подробно разбирать эту функцию и сразу приведу полный листинг с комментариями после всех необходимых переименований переменных:
Листинг функции __prepare_key()
Единственное место, достойное рассмотрения, — это вот эта строка:
*(undefined4 *)key_array[1] = 0x404024;
Как я понял, что здесь кроется строка «VOID»? Дело в том, что 0x404024 — это адрес в адресном пространстве программы, ведущий в секцию .rdata. Двойной клик на это значение позволяет нам как на ладони увидеть, что там находится:

Кстати, это же можно понять из ассемблерного кода для этой строки:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Данные, соответствующие строке «VOID», находятся в самом начале секции .rdata (по нулевому смещению от соответствующего адреса).
Итак, на выходе из этой функции должен быть сформирован двумерный массив со следующими данными:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Шаг 7 — Готовим двоичный файл для крякми
Теперь можем приступить к синтезу двоичного файла. Все исходные данные у нас на руках:
1) проверочные данные («стоп-символы») и их позиции в проверочном массиве;
2) последовательность данных в файле
Давайте восстановим структуру искомого файла по алгоритму работы функции _construct_key(). Итак, последовательность данных в файле будет такова:
Структура файла
Для наглядности я сделал в Excel такую табличку с данными искомого файла:

Здесь в 7-й строке — сами данные в виде символов и чисел, в 6-й строке — их шестнадцатеричные представления, в 8-й строке — размер каждого элемента (в байтах), в 9-й строке — смещение относительно начала файла. Это представление очень удобно, т.к. позволяет вписывать любые строки в будущий файл (отмечены желтой заливкой), при этом значения длин этих строк, а также смещения позиции следующего стоп-символа вычисляются формулами автоматически, как это требует алгоритм программы. Выше (в строках 1-4) приведена структура проверочного массива key_array.
Саму эксельку плюс другие исходные материалы к статье можно скачать по ссылке.
Генерация двоичного файла и проверка
Осталось дело за малым — сгенерировать искомый файл в двоичном формате и скормить его нашей крякми. Для генерации файла я написал простенький скрипт на Python:
Скрипт для генерации файла
Скрипт принимает единственным параметром путь к крякми, затем генерирует в этой же директории двоичный файл с ключом и вызывает крякми с соответствующим параметром, транслируя в консоль вывод программы.
Для конвертации текстовых данных в двоичные используется пакет struct. Метод pack() позволяет записывать двоичные данные по формату, в котором указывается тип данных («B» = «byte», «i» = int и т.д.), а также можно указать порядок следования (“>” = «Big-endian», “<” = «Little-endian»). По умолчанию применяется порядок Little-endian. Т.к. мы уже определили в первой статье, что это именно наш случай, то указываем только тип.
Весь код в целом воспроизводит найденный нами алгоритм программы. В качестве строки, выводимой в случае успеха, я указал «I solved this crackme!» (можно модифицировать этот скрипт, чтобы возможно было указывать любую строку).
Проверяем вывод:

Ура, все работает! Вот так, немного попотев и разобрав пару функций, мы смогли полностью восстановить алгоритм программы и «взломать» ее. Конечно, это всего лишь простая крякми, тестовая программка, да и то 2-го уровня сложности (из 5 предлагаемых на том сайте). В реальности мы будем иметь дело со сложной иерархией вызовов и десятками — сотнями функций, а в некоторых случаях — шифрованными секциями данных, мусорным кодом и прочими приемами обфускации, вплоть до применения внутренних виртуальных машин и P-кода… Но это, как говорится, уже совсем другая история.
Это первый шаг на долгом пути реверсера… Удачи в освоении.












Ебать вы типы +rep вам за статьи и мемы на сайте по типу “Очень злой админ”